Intelligenza artificiale generale, l’idea di un’A.I. intelligente un agente in grado di comprendere e apprendere qualsiasi compito intellettuale che gli esseri umani possono svolgere è stato a lungo una componente della fantascienza. Come A.I. diventa sempre più intelligente, soprattutto grazie alle innovazioni negli strumenti di apprendimento automatico in grado di riscrivere i propri dati codice per imparare da nuove esperienze: fa sempre più parte delle conversazioni reali sull'intelligenza artificiale BENE.
Contenuti
- Costruire mondi
- Le regole del gioco
- Le cose difficili sono facili, le cose facili sono difficili
Ma come misuriamo l’AGI quando arriva? Nel corso degli anni, i ricercatori hanno delineato una serie di possibilità. Il più famoso rimane il test di Turing, in cui un giudice umano interagisce, a scatola chiusa, sia con gli esseri umani che con una macchina, e deve cercare di indovinare quale sia l'uno. Altri due, Robot College Student Test di Ben Goertzel e Nils J. Nilsson's Employment Test, cerca di testare praticamente le capacità di un'intelligenza artificiale vedendo se può conseguire una laurea o svolgere lavori sul posto di lavoro. Un altro, che personalmente preferirei scartare, presuppone che l’intelligenza possa essere misurata dalla capacità di successo di assemblare mobili flatpack in stile Ikea senza problemi.
Video consigliati
Una delle misure AGI più interessanti è stata avanzata dal cofondatore di Apple Steve Wozniak. Woz, come è noto ad amici e ammiratori, suggerisce il Coffee Test. Un'intelligenza generale, ha detto, significherebbe un robot in grado di entrare in qualsiasi casa del mondo, individuare la cucina, preparare una tazza di caffè e poi versarlo in una tazza.
Imparentato
- IA analogica? Sembra pazzesco, ma potrebbe essere il futuro
- Ecco cosa fa un'A.I. che analizza le tendenze. pensa che sarà la prossima grande novità nel campo della tecnologia
- Il futuro dell'intelligenza artificiale: 4 grandi cose a cui prestare attenzione nei prossimi anni
Come con ogni A.I. test di intelligenza, puoi discutere su quanto siano ampi o ristretti i parametri. Tuttavia, l’idea che l’intelligenza debba essere collegata alla capacità di navigare nel mondo reale è intrigante. È anche quello che un nuovo progetto di ricerca cerca di testare.
Costruire mondi
“Negli ultimi anni l’A.I. ha fatto enormi passi avanti nell'addestramento dell'A.I. agenti per svolgere compiti complessi”, Luca Weihs, ricercatore presso l'Allen Institute for AI, un laboratorio di intelligenza artificiale fondato dal defunto co-fondatore di Microsoft Paul Allen, ha dichiarato a Digital Trends.

Weihs ha citato lo sviluppo di A.I. agenti che sono in grado di imparare a farlo giocare ai classici giochi Atari E battere i giocatori umani a Go. Tuttavia, Weihs ha osservato che questi compiti sono “spesso staccati” dal nostro mondo. Mostra un'immagine del mondo reale a un'A.I. addestrato per giocare ai giochi Atari e non avrà idea di cosa sta guardando. È qui che i ricercatori dell’Allen Institute credono di avere qualcosa da offrire.
L'Allen Institute for A.I. ha costruito una sorta di impero immobiliare. Ma questo non è un immobile fisico, quanto un immobile virtuale. Ha sviluppato centinaia di stanze e appartamenti virtuali, tra cui cucine, camere da letto, bagni e soggiorni, in cui A.I. gli agenti possono interagire con migliaia di oggetti. Questi spazi vantano una fisica realistica, il supporto per più agenti e persino stati come caldo e freddo. Lasciando che A.I. gli agenti giocano in questi ambienti, l'idea è che possano costruire una percezione più realistica del mondo.
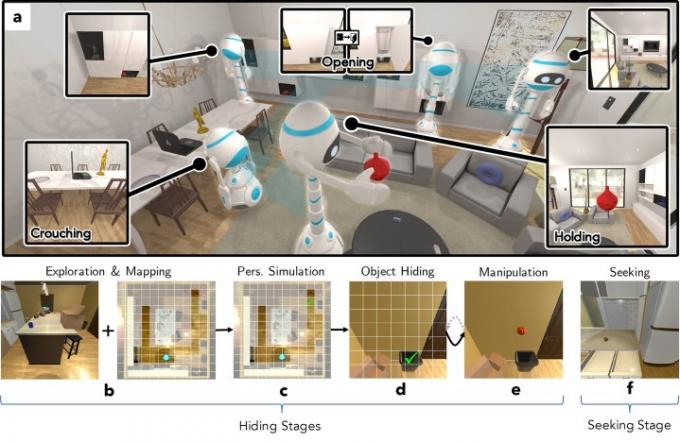
“Nel [nostro nuovo] lavoro, volevamo capire come l’A.I. gli agenti potrebbero conoscere un ambiente realistico giocando a un gioco interattivo al suo interno", ha affermato Weihs. "Per rispondere a questa domanda, abbiamo addestrato due agenti a giocare a Cache, una variante del nascondino, utilizzando l'apprendimento di rinforzo antagonista all'interno del gioco ad alta fedeltà Ambiente AI2-THOR. Attraverso questo gameplay, abbiamo scoperto che i nostri agenti imparavano a rappresentare le singole immagini, avvicinandosi all'esecuzione dei metodi richiedendo milioni di immagini etichettate a mano – e cominciò persino a sviluppare alcune primitive cognitive spesso studiate da [sviluppi] psicologi”.
Le regole del gioco
A differenza del normale nascondino, in Cache i robot, a turno, nascondono oggetti come sturalavandini, pagnotte di pane, pomodori e altro, ognuno dei quali vanta le proprie geometrie individuali. I due agenti - uno che si nasconde, l'altro che cerca - competono quindi per vedere se uno riesce a nascondere con successo l'oggetto all'altro. Ciò comporta una serie di sfide, tra cui l'esplorazione e la mappatura, la comprensione della prospettiva, il nascondimento, la manipolazione degli oggetti e la ricerca. Tutto è simulato accuratamente, anche il requisito che chi si nasconde sia in grado di manipolare l'oggetto che ha in mano e di non lasciarlo cadere.
Utilizzando l'apprendimento per rinforzo profondo, un paradigma di apprendimento automatico basato sull'apprendimento di intraprendere azioni in un ambiente per massimizzare la ricompensa: i robot diventano sempre più bravi a nascondere gli oggetti, oltre a cercarli loro fuori.
“Ciò che rende tutto questo così difficile per le IA è che non vedono il mondo come lo vediamo noi”, ha detto Weihs. “Miliardi di anni di evoluzione hanno fatto sì che, anche da bambini, il nostro cervello traduca in modo efficiente i fotoni in concetti. D'altra parte, un A.I. parte da zero e vede il suo mondo come un'enorme griglia di numeri che poi deve imparare a decodificare in significato. Inoltre, a differenza degli scacchi, dove il mondo è racchiuso ordinatamente in 64 caselle, ogni immagine vista dall'agente cattura solo un piccola fetta dell'ambiente, e quindi deve integrare le sue osservazioni nel tempo per formare una comprensione coerente dell'ambiente mondo."
Per essere chiari, quest’ultimo lavoro non riguarda la costruzione di un’intelligenza artificiale super intelligente. In film come Terminator 2: Il Giorno del Giudizio, il supercomputer Skynet raggiunge l'autocoscienza esattamente alle 2:14, ora di New York, del 29 agosto 1997. Nonostante la data, ormai quasi un quarto di secolo nel nostro specchietto retrovisore collettivo, sembra improbabile che ci sarà un punto di svolta così preciso in cui l’A.I. diventa AGI. Invece, sempre più frutti computazionali – a basso e ad alto rischio – verranno colti finché non avremo finalmente qualcosa che si avvicini a un’intelligenza generalizzata in più domini.
Le cose difficili sono facili, le cose facili sono difficili
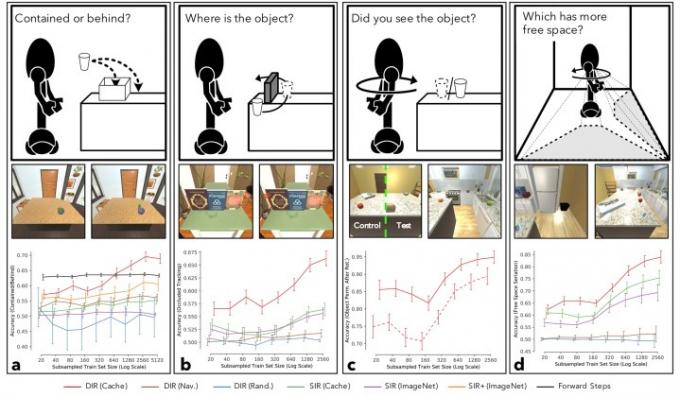
I ricercatori hanno tradizionalmente gravitato verso problemi complessi per l’A.I. risolvere sulla base dell’idea che, se i problemi difficili possono essere risolti, quelli facili non dovrebbero essere troppo indietro. Se riesci a simulare il processo decisionale di un adulto, idee come la permanenza dell'oggetto (l'idea che obietta ancora esistono quando non possiamo vederli) che un bambino impara nei primi mesi di vita lo dimostrano davvero difficile? La risposta è sì – e questo paradosso che, quando si tratta di intelligenza artificiale, il le cose difficili sono spesso facili, e le cose facili sono difficili, è ciò che un lavoro come questo si propone di affrontare.
“Il paradigma più comune per l’addestramento dell’A.I. agenti [coinvolgono] enormi set di dati etichettati manualmente e strettamente focalizzati su un singolo compito, ad esempio il riconoscimento di oggetti”, ha affermato Weihs. “Sebbene questo approccio abbia avuto un grande successo, penso che sia ottimistico credere che possiamo creare manualmente set di dati sufficienti per produrre un sistema di intelligenza artificiale. agente che può agire in modo intelligente nel mondo reale, comunicare con gli esseri umani e risolvere tutti i tipi di problemi che non ha mai incontrato prima. Per fare ciò, credo che dovremo consentire agli agenti di apprendere le primitive cognitive fondamentali che diamo per scontate, consentendo loro di interagire liberamente con il loro mondo. Il nostro lavoro dimostra che l'utilizzo del gameplay per motivare l'A.I. Gli agenti che interagiscono ed esplorano il loro mondo li porta a iniziare ad apprendere questi primitivi - e quindi mostra che il gameplay è una direzione promettente lontano dai set di dati modificati manualmente e verso l'esperienza apprendimento."
UN articolo che descrive questo lavoro sarà presentato alla prossima Conferenza internazionale sulle rappresentazioni dell'apprendimento del 2021.
Raccomandazioni degli editori
- Le illusioni ottiche potrebbero aiutarci a costruire la prossima generazione di intelligenza artificiale
- La formula divertente: perché l'umorismo generato dalle macchine è il Santo Graal dell'A.I.
- Leggi la "scrittura sintetica" stranamente bella di un A.I. che pensa che sia Dio
- Architettura algoritmica: dovremmo lasciare che l’A.I. progettare edifici per noi?
- A.I. sensibile alle emozioni è qui e potrebbe essere nel tuo prossimo colloquio di lavoro



