Inteligencia artificial general, la idea de una A.I. Un agente capaz de comprender y aprender cualquier tarea intelectual que los humanos puedan realizar ha sido durante mucho tiempo un componente de la ciencia ficción. Como A.I. se vuelve cada vez más inteligente, especialmente con avances en herramientas de aprendizaje automático que pueden reescribir sus código para aprender de nuevas experiencias: es cada vez más una parte de las conversaciones reales de inteligencia artificial a medida que avanzan. Bueno.
Contenido
- Construyendo mundos
- Reglas del juego
- Lo difícil es fácil, lo fácil es difícil
Pero, ¿cómo medimos el AGI cuando llega? A lo largo de los años, los investigadores han planteado una serie de posibilidades. La más famosa sigue siendo la prueba de Turing, en la que un juez humano interactúa, sin ser visto, tanto con humanos como con una máquina, y debe intentar adivinar cuál es cuál. Otros dos, el Robot College Student Test de Ben Goertzel y el de Nils J. La Prueba de Empleo de Nilsson busca probar prácticamente las habilidades de una IA al ver si podría obtener un título universitario o realizar trabajos en el lugar de trabajo. Otro, que personalmente me encantaría descartar, postula que la inteligencia puede medirse por la capacidad exitosa de ensamblar muebles planos estilo Ikea sin problemas.
Vídeos recomendados
Una de las medidas AGI más interesantes fue propuesta por el cofundador de Apple, Steve Wozniak. Woz, como lo conocen sus amigos y admiradores, sugiere la prueba del café. Una inteligencia general, dijo, significaría un robot capaz de entrar en cualquier casa del mundo, localizar la cocina, preparar una taza de café recién hecho y luego servirla en una taza.
Relacionado
- ¿IA analógica? Parece una locura, pero podría ser el futuro.
- Esto es lo que hace una IA que analiza tendencias. cree que será la próxima gran novedad en tecnología
- El futuro de la IA: 4 grandes cosas a tener en cuenta en los próximos años
Como ocurre con todos los A.I. prueba de inteligencia, se puede discutir sobre qué tan amplios o estrechos son los parámetros. Sin embargo, la idea de que la inteligencia debería estar vinculada a la capacidad de navegar por el mundo real es intrigante. También es uno que un nuevo proyecto de investigación busca probar.
Construyendo mundos
“En los últimos años, la A.I. La comunidad ha logrado grandes avances en el entrenamiento de A.I. agentes para realizar tareas complejas”, Luca Weihs, dijo a Digital Trends un científico investigador del Instituto Allen de IA, un laboratorio de inteligencia artificial fundado por el fallecido cofundador de Microsoft, Paul Allen.

Weihs citó el desarrollo de A.I. de DeepMind. agentes capaces de aprender a jugar juegos clásicos de Atari y vencer a jugadores humanos en Go. Sin embargo, Weihs señaló que estas tareas “frecuentemente están separadas” de nuestro mundo. Muestre una imagen del mundo real a un A.I. entrenado para jugar juegos de Atari y no tendrá idea de lo que está mirando. Es aquí donde los investigadores del Instituto Allen creen que tienen algo que ofrecer.
El Instituto Allen de A.I. ha construido una especie de imperio inmobiliario. Pero esto no es un inmueble físico, sino un inmueble virtual. Ha desarrollado cientos de habitaciones y apartamentos virtuales, incluidas cocinas, dormitorios, baños y salas de estar, en los que la A.I. Los agentes pueden interactuar con miles de objetos. Estos espacios cuentan con física realista, soporte para múltiples agentes e incluso estados como frío y calor. Al dejar que A.I. Los agentes juegan en estos entornos, la idea es que puedan construir una percepción más realista del mundo.
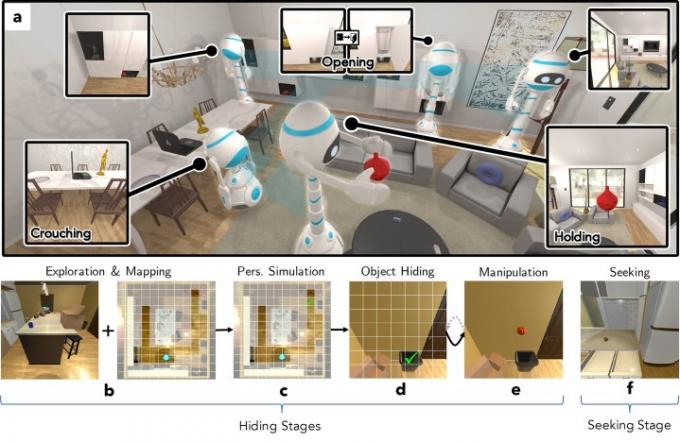
“En [nuestro nuevo] trabajo, queríamos entender cómo la A.I. Los agentes podrían aprender sobre un entorno realista jugando un juego interactivo dentro de él”, dijo Weihs. “Para responder a esta pregunta, entrenamos a dos agentes para que jugaran a Cache, una variante del escondite, utilizando el aprendizaje por refuerzo adversario dentro del sistema de alta fidelidad. Entorno AI2-THOR. A través de este juego, descubrimos que nuestros agentes aprendieron a representar imágenes individuales, acercándose a la ejecución de métodos. requirieron millones de imágenes etiquetadas a mano, e incluso comenzaron a desarrollar algunas primitivas cognitivas a menudo estudiadas por [desarrollistas] psicólogos”.
Reglas del juego
A diferencia del escondite normal, en Cache los robots se turnan para ocultar objetos como desatascadores de inodoros, hogazas de pan, tomates y más, cada uno de los cuales cuenta con sus propias geometrías individuales. Los dos agentes, uno que oculta y el otro que busca, compiten para ver si uno puede ocultar con éxito el objeto al otro. Esto implica una serie de desafíos, incluida la exploración y el mapeo, la comprensión de la perspectiva, el ocultamiento, la manipulación de objetos y la búsqueda. Todo está simulado con precisión, incluso el requisito de que quien se esconde pueda manipular el objeto en su mano y no dejarlo caer.
Uso del aprendizaje por refuerzo profundo: un paradigma de aprendizaje automático basado en aprender a realizar acciones en un entorno para maximizar la recompensa: los robots mejoran cada vez más ocultando los objetos, así como buscando ellos afuera.
"Lo que hace que esto sea tan difícil para las IA es que no ven el mundo como lo vemos nosotros", dijo Weihs. “Miles de millones de años de evolución han logrado que, incluso cuando somos bebés, nuestros cerebros traduzcan eficientemente fotones en conceptos. Por otro lado, una A.I. comienza desde cero y ve su mundo como una enorme cuadrícula de números que luego debe aprender a decodificar para darles significado. Además, a diferencia del ajedrez, donde el mundo está claramente contenido en 64 casillas, cada imagen vista por el agente sólo captura una pequeña porción del medio ambiente, por lo que debe integrar sus observaciones a través del tiempo para formar una comprensión coherente del mundo."
Para ser claros, este último trabajo no se trata de construir una IA súper inteligente. en películas como Terminator 2: El día del juicio final, el superordenador Skynet alcanza la autoconciencia exactamente a las 2.14 a. m., hora del Este, el 29 de agosto de 1997. A pesar de la fecha, ahora de casi un cuarto de siglo en nuestro espejo retrovisor colectivo, parece poco probable que haya un punto de inflexión tan preciso cuando la IA regular. se convierte en AGI. En cambio, se recogerán cada vez más frutos computacionales (al alcance de la mano y al alcance de la mano) hasta que finalmente tengamos algo que se acerque a una inteligencia generalizada en múltiples dominios.
Lo difícil es fácil, lo fácil es difícil
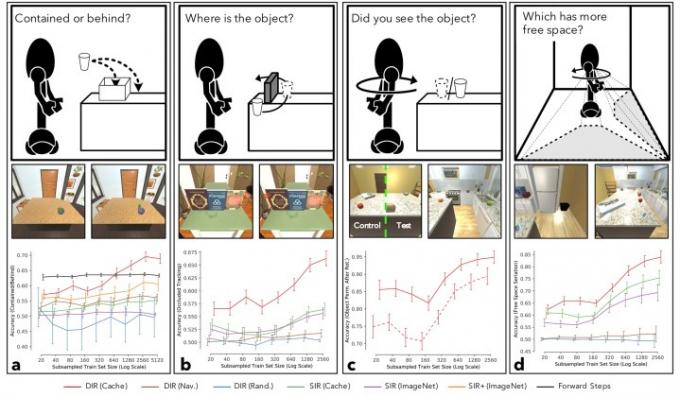
Los investigadores tradicionalmente se han centrado en problemas complejos para la IA. resolver basándose en la idea de que, si los problemas difíciles pueden solucionarse, los fáciles no deberían quedarse atrás. Si se puede simular la toma de decisiones de un adulto, ¿podrían ideas como la permanencia del objeto (la idea de que los objetos todavía existen cuando no podemos verlos) que un niño aprende durante los primeros meses de su vida realmente demuestran que ¿difícil? La respuesta es sí, y esta paradoja de que, cuando se trata de IA, la Lo difícil suele ser fácil y lo fácil es difícil., es lo que un trabajo como este se propone abordar.
“El paradigma más común para entrenar A.I. agentes [implica] enormes conjuntos de datos etiquetados manualmente y centrados estrechamente en una sola tarea, por ejemplo, reconocer objetos”, dijo Weihs. “Si bien este enfoque ha tenido un gran éxito, creo que es optimista creer que podemos crear manualmente suficientes conjuntos de datos para producir una IA. agente que puede actuar de forma inteligente en el mundo real, comunicarse con humanos y resolver todo tipo de problemas que no ha encontrado antes. Para hacer esto, creo que necesitaremos dejar que los agentes aprendan los primitivos cognitivos fundamentales que damos por sentado, permitiéndoles interactuar libremente con su mundo. Nuestro trabajo muestra que usar el juego para motivar a la A.I. agentes para interactuar y explorar su mundo hace que comiencen a aprender estos primitivos, y por lo tanto muestra que el juego es una dirección prometedora que se aleja de los conjuntos de datos etiquetados manualmente y se acerca a la experiencia. aprendiendo."
A artículo que describe este trabajo se presentará en la próxima Conferencia Internacional sobre Representaciones del Aprendizaje de 2021.
Recomendaciones de los editores
- Las ilusiones ópticas podrían ayudarnos a construir la próxima generación de IA
- La fórmula divertida: por qué el humor generado por máquinas es el santo grial de la IA
- Lea la inquietantemente hermosa "escritura sintética" de una IA. que piensa que es dios
- Arquitectura algorítmica: ¿Deberíamos dejar que la A.I. ¿Diseñar edificios para nosotros?
- IA con detección de emociones está aquí, y podría estar en tu próxima entrevista de trabajo



