OCR 텍스트 인식을 선택하는 메뉴 옵션
하드카피 문서를 스캔하여 PDF 형식으로 저장할 때 컴퓨터는 스캔한 텍스트 페이지와 사진의 차이를 인식하지 못합니다. 따라서 페이지에서 복사하여 붙여넣을 텍스트를 검색하거나 선택할 수 없습니다. 텍스트를 검색하거나 선택하려면 문서에서 광학 문자 인식(OCR)을 실행해야 합니다. Adobe Acrobat Professional은 이 기능을 제공하지만 Adobe Acrobat 무료 버전은 제공하지 않습니다. Acrobat Professional이 없는 경우 PDF 문서에서 OCR을 실행할 수 있는 Acrobat Professional 이외의 소프트웨어가 있으며 웹 검색을 통해 찾을 수 있습니다.
1 단계
Adobe Acrobat Professional을 로드합니다. Acrobat Professional의 OCR 기능은 웹 브라우저 플러그인을 통해 사용할 수 없으므로 실제 프로그램을 로드해야 합니다.
오늘의 비디오
2 단계
복사하여 붙여넣기를 선택할 수 없는 텍스트가 포함된 PDF 문서를 로드합니다. 이러한 문서는 일반적으로 문서를 스캔하고 Adobe Acrobat PDF 형식으로 문서를 저장하여 생성됩니다. (샘플 문서로 연습하려면 리소스를 참조하세요.)
3단계
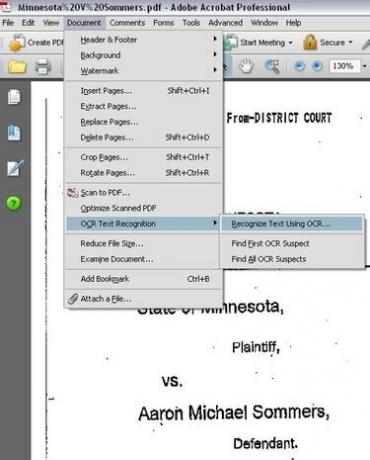
OCR 텍스트 인식을 선택하는 메뉴 옵션
문서에서 OCR을 실행합니다. Adobe Acrobat Professional에서 "문서" 메뉴를 클릭한 다음 "OCR 텍스트 인식"을 선택한 다음 "OCR을 사용하여 텍스트 인식"을 클릭합니다.
4단계
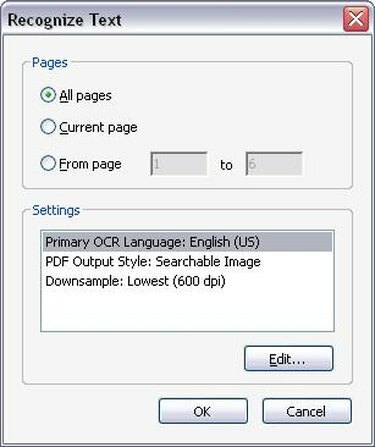
OCR 옵션
해당 OCR 옵션을 선택합니다. "OCR을 사용하여 텍스트 인식"을 클릭하면 OCR을 실행할 페이지 범위를 선택하라는 새 창이 나타납니다. 전체 PDF 파일에서 OCR을 실행하거나 OCR 인식을 몇 페이지로만 제한할 수 있습니다. OCR을 실행할 페이지 수를 선택한 후 "확인"을 클릭합니다. 이제 Acrobat Professional이 문서 페이지의 텍스트를 인식하기 시작합니다.
5단계
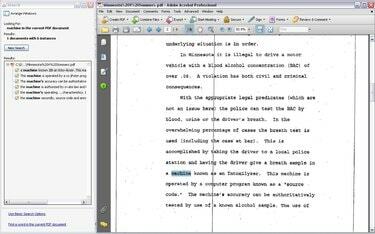
OCR: 검색 및 선택 가능한 PDF 파일 생성
OCR이 완료되면 텍스트를 검색하고 Microsoft Word에서 추출한 PDF에서와 마찬가지로 텍스트를 복사하여 붙여넣습니다. 그러나 OCR 기술은 완벽하지 않습니다. OCR은 특정 단어를 제대로 인식하지 못하고 일부 텍스트가 완전히 누락될 수 있습니다. OCR은 텍스트의 완벽하게 깨끗한 이미지에서 가장 잘 작동하며, 이는 스캔한 문서에서 항상 가능한 것은 아닙니다.


