Valikon vaihtoehdot OCR-tekstin tunnistus
Kun paperikopio skannataan ja tallennetaan PDF-muotoon, tietokone ei tiedä eroa skannatun tekstisivun ja valokuvan välillä. Näin ollen et voi etsiä tai valita sivulta mitään tekstiä kopioitavaksi ja liitettäväksi. Jos haluat etsiä tai valita tekstiä, sinun on suoritettava optinen merkintunnistus (OCR) asiakirjassa. Adobe Acrobat Professional tarjoaa tämän toiminnon, mutta Adobe Acrobatin ilmainen versio ei. Jos sinulla ei ole Acrobat Professionalia, huomaa, että PDF-dokumentin tekstintunnistusta varten on olemassa muita ohjelmistoja kuin Acrobat Professional, ja ne löytyvät netistä etsimällä.
Vaihe 1
Lataa Adobe Acrobat Professional. Acrobat Professionalin OCR-ominaisuus ei ole käytettävissä verkkoselaimen laajennuksen kautta, joten varsinaisen ohjelman lataaminen on välttämätöntä.
Päivän video
Vaihe 2
Lataa PDF-dokumentti, jossa on tekstiä, jota et voi valita kopioitavaksi ja liitettäväksi. Tällaiset asiakirjat tuotetaan yleensä skannaamalla asiakirja ja tallentamalla asiakirja Adobe Acrobat PDF -muotoon. (Katso esimerkkiasiakirjan resurssit, jos haluat harjoitella sellaisen kanssa.)
Vaihe 3
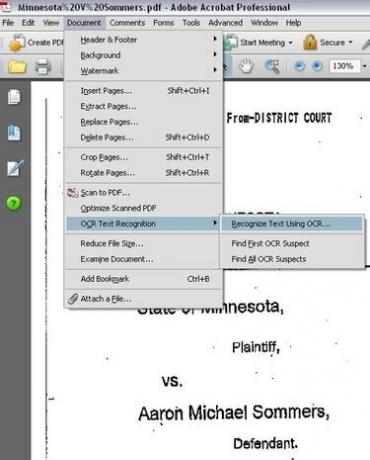
Valikon vaihtoehdot OCR-tekstin tunnistus
Suorita OCR asiakirjassa. Napsauta Adobe Acrobat Professionalissa "Dokumentti"-valikkoa, valitse sitten "OCR-tekstin tunnistus" ja napsauta sitten "Tunnista teksti OCR: lla".
Vaihe 4
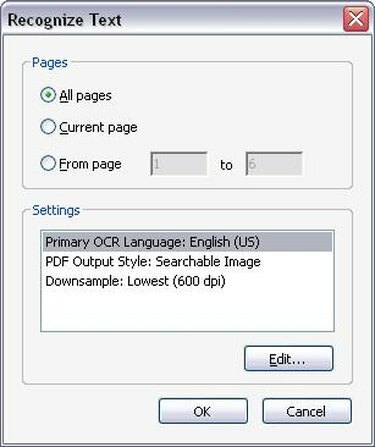
OCR-asetukset
Valitse sopivat OCR-asetukset. Kun napsautat "Tunnista teksti OCR: lla", uusi ikkuna avautuu, jossa sinua pyydetään valitsemaan sivualue, jolla haluat suorittaa OCR: n. Voit suorittaa OCR: n koko PDF-tiedostolle tai voit rajoittaa OCR-tunnistuksen vain muutamalle sivulle. Kun olet valinnut kuinka monella sivulla haluat suorittaa OCR: n, napsauta "OK". Acrobat Professional alkaa nyt tunnistaa tekstiä asiakirjasi sivuilla.
Vaihe 5
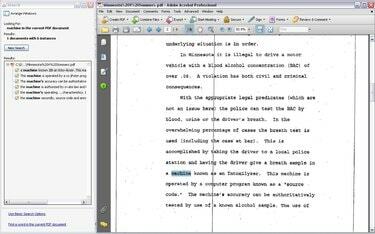
OCR: Luo haettavan ja valittavissa olevan PDF-tiedoston
Etsi tekstiä, kun OCR on valmis, ja kopioi ja liitä tekstiä aivan kuten voisit tehdä Microsoft Wordista tislatun PDF-tiedoston kanssa. Huomaa kuitenkin, että OCR-tekniikka ei ole täydellinen. Tekstintunnistus ei välttämättä tunnista tiettyjä sanoja oikein ja osa tekstistä saattaa jäädä kokonaan huomaamatta. Tekstintunnistus toimii parhaiten täysin selkeillä tekstikuvilla, mikä ei aina ole mahdollista skannatuissa asiakirjoissa.



