Параметри меню для вибору розпізнавання тексту OCR
Коли друкований документ сканується та зберігається у форматі PDF, комп’ютер не знає різниці між відсканованою сторінкою тексту та фотографією. Таким чином, ви не можете шукати або вибирати будь-який текст на сторінці для копіювання та вставки. Якщо ви хочете шукати або виділяти текст, потрібно запустити в документі оптичне розпізнавання символів (OCR). Adobe Acrobat Professional надає цю функцію, але безкоштовна версія Adobe Acrobat — ні. Якщо у вас немає Acrobat Professional, зверніть увагу, що крім Acrobat Professional існує програмне забезпечення для розпізнавання тексту PDF-документа, яке можна знайти за допомогою пошуку в Інтернеті.
Крок 1
Завантажте Adobe Acrobat Professional. Функція OCR Acrobat Professional недоступна через плагін для веб-переглядача, тому необхідно завантажити фактичну програму.
Відео дня
Крок 2
Завантажте PDF-документ з текстом, який ви не можете вибрати для копіювання та вставки. Такі документи зазвичай виготовляються шляхом сканування документа та збереження документа у форматі Adobe Acrobat PDF. (Зразок документа див. у Ресурсах, якщо ви хочете потренуватися з ним.)
Крок 3
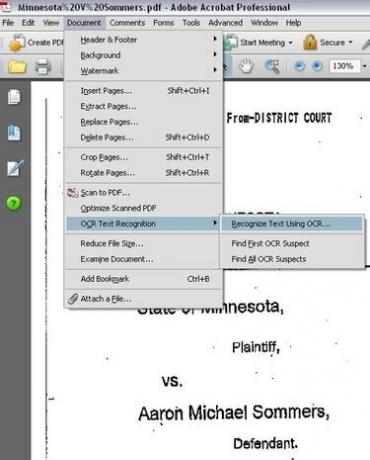
Параметри меню для вибору розпізнавання тексту OCR
Запустіть OCR на документі. У Adobe Acrobat Professional натисніть меню «Документ», потім виберіть «Розпізнавання тексту OCR», а потім натисніть «Розпізнати текст за допомогою OCR».
Крок 4
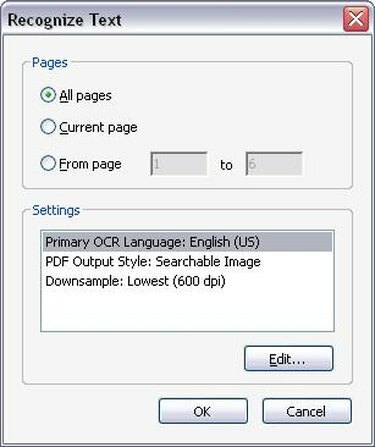
Параметри OCR
Виберіть відповідні параметри OCR. Після того, як ви натиснете «Розпізнати текст за допомогою OCR», з’явиться нове вікно з проханням вибрати діапазон сторінок, на якому ви хочете запустити OCR. Ви можете запустити OCR для всього PDF-файлу або обмежити розпізнавання OCR лише кількома сторінками. Вибравши кількість сторінок, на яких потрібно запустити OCR, натисніть «ОК». Тепер Acrobat Professional почне розпізнавати текст на сторінках вашого документа.
Крок 5
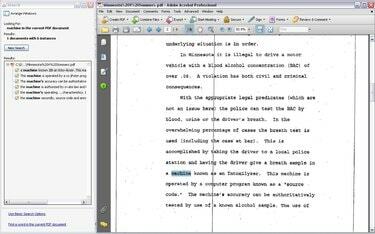
OCR: створює PDF-файл із можливістю пошуку та вибору
Після завершення OCR шукайте текст, копіюйте та вставляйте текст так само, як і PDF-файл із Microsoft Word. Однак зауважте, що технологія OCR не є ідеальною. OCR може неправильно розпізнавати певні слова і може повністю пропустити деякий текст. OCR найкраще працює з ідеально чіткими зображеннями тексту, що не завжди можливо зі сканованими документами.


