ปัญญาประดิษฐ์ทั่วไป แนวคิดของ A.I. ตัวแทนที่สามารถเข้าใจและเรียนรู้งานทางปัญญาใดๆ ที่มนุษย์สามารถทำได้ เป็นส่วนหนึ่งของนิยายวิทยาศาสตร์มานานแล้ว ในฐานะเอไอ ฉลาดขึ้นเรื่อยๆ โดยเฉพาะเมื่อมีความก้าวหน้าในเครื่องมือการเรียนรู้ของเครื่องที่สามารถเขียนใหม่ได้ รหัสเพื่อเรียนรู้จากประสบการณ์ใหม่ - มันเป็นส่วนหนึ่งของการสนทนาปัญญาประดิษฐ์จริงมากขึ้นเรื่อย ๆ ดี.
สารบัญ
- การสร้างโลก
- กฎของเกม
- เรื่องยากก็ง่าย เรื่องง่ายก็ยาก
แต่เราจะวัด AGI ได้อย่างไรเมื่อมาถึง? ในช่วงหลายปีที่ผ่านมา นักวิจัยได้ระบุความเป็นไปได้หลายประการ สิ่งที่มีชื่อเสียงที่สุดยังคงเป็นการทดสอบทัวริง ซึ่งผู้ตัดสินที่เป็นมนุษย์โต้ตอบกับทั้งมนุษย์และเครื่องจักรโดยมองไม่เห็น และต้องพยายามเดาว่าอันไหนคืออันไหน อีกสองคนคือ Robot College Student Test ของ Ben Goertzel และ Nils J. แบบทดสอบการจ้างงานของ Nilsson พยายามทดสอบความสามารถของ A.I. ในทางปฏิบัติโดยดูว่าจะสามารถได้รับปริญญาระดับวิทยาลัยหรือทำงานในสถานที่ทำงานได้หรือไม่ อีกประการหนึ่งซึ่งโดยส่วนตัวแล้วฉันควรจะชอบลดราคาโดยบอกว่าความฉลาดอาจวัดได้จากความสามารถในการประกอบเฟอร์นิเจอร์ Flatpack สไตล์ Ikea ที่ประสบความสำเร็จโดยไม่มีปัญหา
วิดีโอแนะนำ
หนึ่งในมาตรการ AGI ที่น่าสนใจที่สุดได้รับการเสนอโดย Steve Wozniak ผู้ร่วมก่อตั้ง Apple Woz เป็นที่รู้จักในหมู่เพื่อนฝูงและผู้ชื่นชม แนะนำ Coffee Test เขากล่าวว่าสติปัญญาทั่วไปหมายถึงหุ่นยนต์ที่สามารถเข้าไปในบ้านใดก็ได้ในโลก ค้นหาห้องครัว ชงกาแฟสดสักแก้ว แล้วเทลงในแก้ว
ที่เกี่ยวข้อง
- อะนาล็อกเอไอ? ฟังดูบ้าบอ แต่อาจจะเป็นอนาคตก็ได้
- นี่คือสิ่งที่ A.I. วิเคราะห์แนวโน้ม คิดว่าจะเป็นสิ่งที่ยิ่งใหญ่ต่อไปในเทคโนโลยี
- อนาคตของ A.I.: 4 เรื่องสำคัญที่ต้องจับตามองในอีกไม่กี่ปีข้างหน้า
เช่นเดียวกับทุกๆ A.I. การทดสอบสติปัญญา คุณสามารถโต้แย้งได้ว่าพารามิเตอร์นั้นกว้างหรือแคบเพียงใด อย่างไรก็ตาม แนวคิดที่ว่าความฉลาดควรเชื่อมโยงกับความสามารถในการสำรวจโลกแห่งความเป็นจริงนั้นน่าสนใจมาก นอกจากนี้ยังเป็นสิ่งหนึ่งที่โครงการวิจัยใหม่พยายามทดสอบด้วย
การสร้างโลก
“ในช่วงไม่กี่ปีที่ผ่านมา A.I. ชุมชนมีความก้าวหน้าอย่างมากในการฝึกอบรม A.I. ตัวแทนเพื่อทำงานที่ซับซ้อน” ลูก้า ไวห์สนักวิทยาศาสตร์การวิจัยจาก Allen Institute for AI ซึ่งเป็นห้องปฏิบัติการปัญญาประดิษฐ์ที่ก่อตั้งโดย Paul Allen ผู้ร่วมก่อตั้ง Microsoft ผู้ล่วงลับกล่าวกับ Digital Trends

Weihs อ้างถึงการพัฒนา A.I. ตัวแทนที่สามารถเรียนรู้ได้ เล่นเกม Atari สุดคลาสสิก และ เอาชนะผู้เล่นที่เป็นมนุษย์ที่ Go. อย่างไรก็ตาม Weihs ตั้งข้อสังเกตว่างานเหล่านี้ "แยกออกจากโลกของเราบ่อยครั้ง" แสดงภาพโลกแห่งความเป็นจริงให้กับ A.I. ได้รับการฝึกฝนให้เล่นเกม Atari และมันไม่รู้ว่ากำลังดูอะไรอยู่ ที่นี่เป็นที่ที่นักวิจัยของสถาบัน Allen เชื่อว่าพวกเขามีบางสิ่งบางอย่างที่จะนำเสนอ
สถาบันอัลเลนเพื่อ A.I. ได้สร้างอาณาจักรอสังหาริมทรัพย์ขึ้นมา แต่นี่ไม่ใช่อสังหาริมทรัพย์ทางกายภาพ มากเท่ากับเป็นอสังหาริมทรัพย์เสมือนจริง บริษัทได้พัฒนาห้องและอพาร์ตเมนต์เสมือนจริงหลายร้อยห้อง รวมถึงห้องครัว ห้องนอน ห้องน้ำ และห้องนั่งเล่น โดยที่ A.I. ตัวแทนสามารถโต้ตอบกับวัตถุนับพันรายการ พื้นที่เหล่านี้มีฟิสิกส์ที่สมจริง รองรับเอเจนต์หลายราย และแม้แต่สภาวะร้อนและเย็น โดยให้ A.I. ตัวแทนเล่นในสภาพแวดล้อมเหล่านี้ แนวคิดก็คือพวกเขาสามารถสร้างการรับรู้โลกที่สมจริงยิ่งขึ้นได้
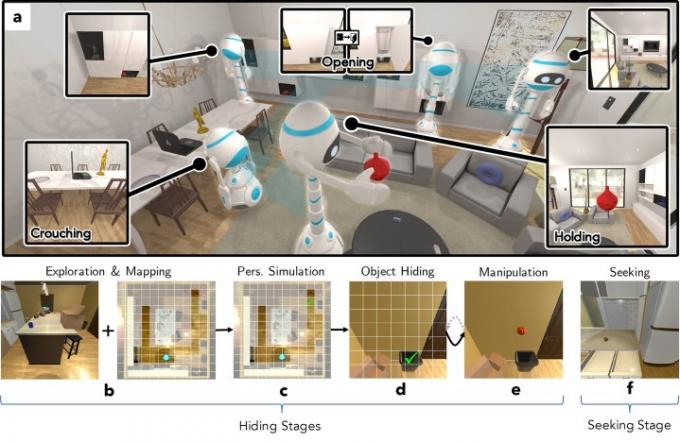
“ในงาน [ใหม่ของเรา] เราต้องการทำความเข้าใจว่า A.I. เจ้าหน้าที่สามารถเรียนรู้เกี่ยวกับสภาพแวดล้อมที่สมจริงโดยการเล่นเกมแบบโต้ตอบภายในนั้น” Weihs กล่าว “เพื่อตอบคำถามนี้ เราได้ฝึกอบรมเจ้าหน้าที่สองคนให้เล่น Cache ซึ่งเป็นรูปแบบซ่อนหา โดยใช้การเรียนรู้การเสริมกำลังของฝ่ายตรงข้ามภายในความเที่ยงตรงสูง สภาพแวดล้อม AI2-THOR. จากการเล่นเกมนี้ เราพบว่าตัวแทนของเราเรียนรู้ที่จะนำเสนอภาพแต่ละภาพ โดยเข้าใกล้ประสิทธิภาพของวิธีการต่างๆ ต้องใช้รูปภาพที่ติดป้ายกำกับด้วยมือนับล้าน - และแม้กระทั่งเริ่มพัฒนาความรู้ความเข้าใจเบื้องต้นบางอย่างที่มักศึกษาโดย [การพัฒนา] นักจิตวิทยา”
กฎของเกม
ต่างจากการซ่อนหาทั่วไปใน Cache บอทจะผลัดกันซ่อนสิ่งของต่างๆ เช่น ที่ชักโครก ขนมปัง มะเขือเทศ และอื่นๆ อีกมากมาย ซึ่งแต่ละบอทจะมีรูปทรงเรขาคณิตของตัวเอง เจ้าหน้าที่ทั้งสองคน — คนหนึ่งเป็นผู้ซ่อน และอีกคนเป็นผู้แสวงหา — จากนั้นแข่งขันกันเพื่อดูว่ามีใครสามารถซ่อนวัตถุจากอีกคนหนึ่งได้สำเร็จหรือไม่ สิ่งนี้เกี่ยวข้องกับความท้าทายหลายประการ รวมถึงการสำรวจและการทำแผนที่ การทำความเข้าใจมุมมอง การซ่อน การจัดการกับวัตถุ และการแสวงหา ทุกอย่างได้รับการจำลองอย่างแม่นยำ แม้กระทั่งข้อกำหนดที่ผู้ซ่อนควรจะสามารถจัดการวัตถุในมือได้และไม่ทำหล่น
การใช้การเรียนรู้แบบเสริมกำลังเชิงลึก — กระบวนทัศน์แมชชีนเลิร์นนิงที่อิงจากการเรียนรู้ที่จะดำเนินการใน สภาพแวดล้อมเพื่อเพิ่มรางวัล — บอทจะดีขึ้นเรื่อยๆ ในการซ่อนวัตถุ เช่นเดียวกับการค้นหา พวกเขาออกไป
“สิ่งที่ทำให้สิ่งนี้ยากสำหรับ A.I. ก็คือพวกเขาไม่ได้มองโลกในแบบที่เราทำ” Weihs กล่าว “วิวัฒนาการหลายพันล้านปีทำให้สมองของเราแปลโฟตอนเป็นแนวคิดได้อย่างมีประสิทธิภาพ แม้ในขณะที่ทารก ในทางกลับกัน A.I. เริ่มต้นจากศูนย์และมองโลกเป็นตารางตัวเลขขนาดใหญ่ซึ่งจะต้องเรียนรู้ที่จะถอดรหัสเป็นความหมาย ยิ่งไปกว่านั้น ไม่เหมือนกับหมากรุกตรงที่โลกถูกบรรจุไว้อย่างเรียบร้อยใน 64 สี่เหลี่ยม ทุกภาพที่เจ้าหน้าที่มองเห็นจะบันทึกเพียง ชิ้นส่วนเล็กๆ ของสภาพแวดล้อม ดังนั้นจึงต้องบูรณาการการสังเกตผ่านกาลเวลาเพื่อสร้างความเข้าใจที่สอดคล้องกันเกี่ยวกับ โลก."
เพื่อให้ชัดเจน งานล่าสุดนี้ไม่ได้เกี่ยวกับการสร้าง A.I อัจฉริยะขั้นสูง ในภาพยนตร์เช่น Terminator 2: วันพิพากษาซูเปอร์คอมพิวเตอร์ Skynet บรรลุการตระหนักรู้ในตนเองเมื่อเวลา 2.14 น. ตามเวลาตะวันออกของวันที่ 29 สิงหาคม 1997 แม้ว่าจะเป็นเวลาเกือบหนึ่งในสี่ศตวรรษในกระจกมองหลังของเราแล้ว ดูเหมือนว่าไม่น่าเป็นไปได้ที่จะมีจุดเปลี่ยนที่แม่นยำเช่นนี้เมื่อ A.I. กลายเป็นเอจีไอ ในทางกลับกัน ผลไม้ที่มีการคำนวณมากขึ้นเรื่อยๆ ทั้งแบบห้อยต่ำและห้อยสูง จะถูกดึงออกมา จนกระทั่งในที่สุดเราก็มีบางอย่างที่เข้าใกล้ความฉลาดทั่วไปในหลายโดเมน
เรื่องยากก็ง่าย เรื่องง่ายก็ยาก
นักวิจัยมักจะมุ่งสู่ปัญหาที่ซับซ้อนสำหรับ A.I. โดยยึดแนวคิดที่ว่าถ้าปัญหายากๆ สามารถจัดการได้ ปัญหาที่ง่ายก็ไม่ควรล้าหลังจนเกินไป หากคุณสามารถจำลองการตัดสินใจของผู้ใหญ่ได้ แนวคิดต่างๆ เช่น ความคงทนของวัตถุ (แนวคิดที่ว่าวัตถุยังคงนิ่งอยู่) มีอยู่เมื่อเรามองไม่เห็น) การที่เด็กเรียนรู้ภายในสองสามเดือนแรกของชีวิตพิสูจน์ให้เห็นว่าจริงๆ ยาก? คำตอบคือใช่ และความขัดแย้งนี้ เมื่อพูดถึง A.I ของยากมักง่าย ของง่ายก็ยากเป็นสิ่งที่งานเช่นนี้กำหนดไว้เพื่อกล่าวถึง
“กระบวนทัศน์ที่พบบ่อยที่สุดสำหรับการฝึก A.I. ตัวแทน [เกี่ยวข้องกับ] ชุดข้อมูลขนาดใหญ่ที่ติดป้ายกำกับด้วยตนเองซึ่งเน้นไปที่งานเดียวโดยเฉพาะ เช่น การจดจำวัตถุ” Weihs กล่าว “แม้ว่าแนวทางนี้จะประสบความสำเร็จอย่างมาก แต่ผมคิดว่าเป็นการดีที่จะเชื่อว่าเราสามารถสร้างชุดข้อมูลได้เพียงพอที่จะสร้าง A.I. ตัวแทนที่สามารถทำหน้าที่อย่างชาญฉลาดในโลกแห่งความเป็นจริง สื่อสารกับมนุษย์ และแก้ไขปัญหาทุกประเภทที่ไม่เคยพบมาก่อน ในการทำเช่นนี้ ฉันเชื่อว่าเราจะต้องปล่อยให้ตัวแทนเรียนรู้พื้นฐานการรับรู้ขั้นพื้นฐานที่เรามองข้ามไป โดยปล่อยให้พวกเขามีปฏิสัมพันธ์กับโลกของพวกเขาได้อย่างอิสระ งานของเราแสดงให้เห็นว่าการใช้การเล่นเกมเพื่อกระตุ้น A.I. ตัวแทนในการโต้ตอบและสำรวจโลกของพวกเขาส่งผลให้พวกเขาเริ่มเรียนรู้ สิ่งดั้งเดิมเหล่านี้ - และด้วยเหตุนี้จึงแสดงให้เห็นว่าการเล่นเกมเป็นทิศทางที่มีแนวโน้มห่างจากชุดข้อมูลที่ได้รับการควบคุมด้วยตนเองและไปสู่ประสบการณ์ การเรียนรู้."
ก กระดาษอธิบายงานนี้ จะถูกนำเสนอในการประชุมนานาชาติว่าด้วยการนำเสนอการเรียนรู้ประจำปี 2021 ที่จะมีขึ้น
คำแนะนำของบรรณาธิการ
- ภาพลวงตาสามารถช่วยให้เราสร้าง AI รุ่นต่อไปได้
- สูตรตลก: ทำไมอารมณ์ขันที่สร้างโดยเครื่องจักรจึงเป็นจอกศักดิ์สิทธิ์ของ A.I.
- อ่าน 'พระคัมภีร์สังเคราะห์' ที่สวยงามน่าขนลุกของ A.I. ที่คิดว่าเป็นพระเจ้า
- สถาปัตยกรรมอัลกอริทึม: เราควรปล่อยให้ A.I. ออกแบบอาคารให้เราเหรอ?
- A.I. การตรวจจับอารมณ์ มาแล้ว และอาจอยู่ในการสัมภาษณ์งานครั้งถัดไปของคุณ



