Menyalternativ för att välja OCR-textigenkänning
När ett papperskopia skannas och sparas i PDF-format, vet inte en dator skillnaden mellan din skannade textsida och ett fotografi. Du kan alltså inte söka efter eller markera någon text på sidan att kopiera och klistra in. Om du vill söka eller markera text måste du köra optisk teckenigenkänning (OCR) på dokumentet. Adobe Acrobat Professional tillhandahåller denna funktion, men gratisversionen av Adobe Acrobat gör det inte. Om du inte har Acrobat Professional, observera att annan programvara än Acrobat Professional finns för att köra OCR på ett PDF-dokument och kan hittas genom att söka på webben.
Steg 1
Ladda Adobe Acrobat Professional. OCR-funktionen i Acrobat Professional är inte tillgänglig via webbläsarens plugin, så det är nödvändigt att ladda det faktiska programmet.
Dagens video
Steg 2
Ladda ett PDF-dokument med text som du inte kan välja att kopiera och klistra in. Sådana dokument produceras vanligtvis genom att skanna ett dokument och spara dokumentet i Adobe Acrobat PDF-format. (Se Resurser för ett exempeldokument, om du vill öva med ett.)
Steg 3
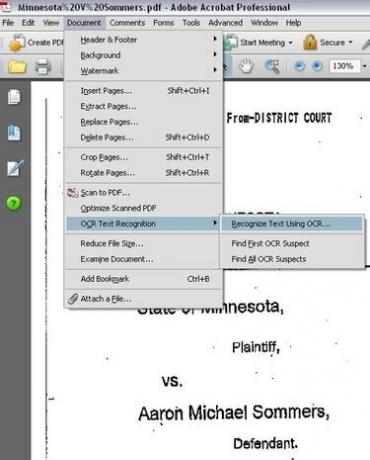
Menyalternativ för att välja OCR-textigenkänning
Kör OCR på dokumentet. I Adobe Acrobat Professional, klicka på "Dokument"-menyn, välj sedan "OCR-textigenkänning" och klicka sedan på "Känn igen text med OCR."
Steg 4
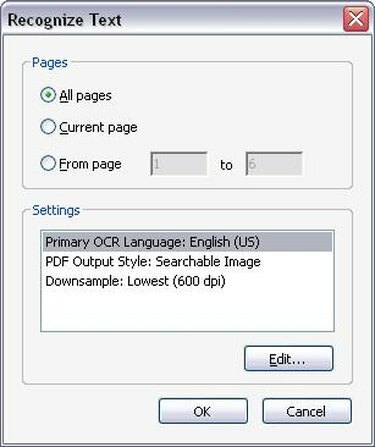
OCR-alternativ
Välj de tillämpliga OCR-alternativen. När du klickar på "Känn igen text med OCR" kommer ett nytt fönster att dyka upp som ber dig att välja sidintervallet där du vill köra OCR. Du kan köra OCR på hela PDF-filen, eller så kan du begränsa OCR-igenkänningen till endast ett fåtal sidor. När du har valt hur många sidor du vill köra OCR på klickar du på "OK". Acrobat Professional börjar nu känna igen texten på sidorna i ditt dokument.
Steg 5
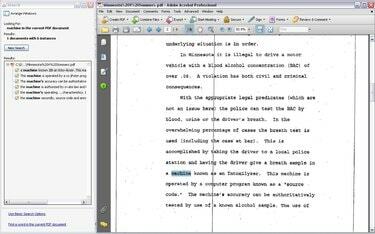
OCR: Skapar en sökbar och valbar PDF-fil
Sök efter text, när OCR är klar, och kopiera och klistra in text precis som du kunde med en PDF destillerad från Microsoft Word. Observera dock att OCR-tekniken inte är perfekt. OCR kanske inte känner igen vissa ord korrekt och kan missa viss text helt. OCR fungerar bäst med helt tydliga bilder av texten, något som inte alltid är möjligt med skannade dokument.