Artificiell allmän intelligens, idén om en intelligent A.I. agent som kan förstå och lära sig alla intellektuella uppgifter som människor kan göra, har länge varit en del av science fiction. Som A.I. blir smartare och smartare — särskilt med genombrott inom maskininlärningsverktyg som kan skriva om sina kod för att lära av nya erfarenheter – det är i allt större utsträckning en del av verkliga konstgjorda intelligenskonversationer som väl.
Innehåll
- Bygga världar
- Spelets regler
- Hårda grejer är lätta, lätta grejer är svårt
Men hur mäter vi AGI när det kommer fram? Under årens lopp har forskare lagt upp en rad möjligheter. Det mest kända är Turing-testet, där en mänsklig domare interagerar, osynlig, med både människor och en maskin, och måste försöka gissa vilken som är vilken. Två andra, Ben Goertzels Robot College Student Test och Nils J. Nilssons anställningstest, försök att praktiskt testa en A.I: s förmågor genom att se om den skulle kunna ta en högskoleexamen eller utföra arbetsplatsjobb. En annan, som jag personligen skulle älska att rabattera, hävdar att intelligens kan mätas genom den framgångsrika förmågan att montera flatpackmöbler i Ikea-stil utan problem.
Rekommenderade videor
En av de mest intressanta AGI-åtgärderna lades fram av Apples medgrundare Steve Wozniak. Woz, som han är känd för vänner och beundrare, föreslår kaffetestet. En allmän intelligens, sa han, skulle innebära en robot som kan gå in i vilket hus som helst i världen, lokalisera köket, brygga upp en ny kopp kaffe och sedan hälla upp den i en mugg.
Relaterad
- Analog A.I.? Det låter galet, men det kanske är framtiden
- Här är vad en trendanalyserande A.I. tror kommer att bli nästa stora grej inom teknik
- Framtiden för A.I.: 4 stora saker att titta på under de närmaste åren
Som med alla A.I. intelligenstest kan man argumentera om hur breda eller smala parametrarna är. Men tanken att intelligens ska kopplas till en förmåga att navigera genom den verkliga världen är spännande. Det är också något som ett nytt forskningsprojekt försöker testa.
Bygga världar
"Under de senaste åren har A.I. community har gjort enorma framsteg när det gäller att träna A.I. agenter för att utföra komplexa uppgifter” Luca Weihs, en forskare vid Allen Institute for AI, ett artificiell intelligenslabb grundat av den sena Microsoft-grundaren Paul Allen, berättade för Digital Trends.

Weihs citerade DeepMinds utveckling av A.I. agenter som kan lära sig spela klassiska Atari-spel och slå mänskliga spelare på Go. Weihs noterade dock att dessa uppgifter "ofta är fristående" från vår värld. Visa en bild av den verkliga världen för en A.I. tränad för att spela Atari-spel, och den har ingen aning om vad den tittar på. Det är här som forskarna från Allen Institute tror att de har något att erbjuda.
Allen Institute for A.I. har byggt upp något av ett fastighetsimperium. Men det här är inte fysiska fastigheter, så mycket som det är virtuella fastigheter. Det har utvecklat hundratals virtuella rum och lägenheter – inklusive kök, sovrum, badrum och vardagsrum – där A.I. agenter kan interagera med tusentals objekt. Dessa utrymmen har realistisk fysik, stöd för flera agenter och till och med tillstånd som varmt och kallt. Genom att låta A.I. agenter spelar i dessa miljöer är tanken att de kan bygga upp en mer realistisk uppfattning om världen.
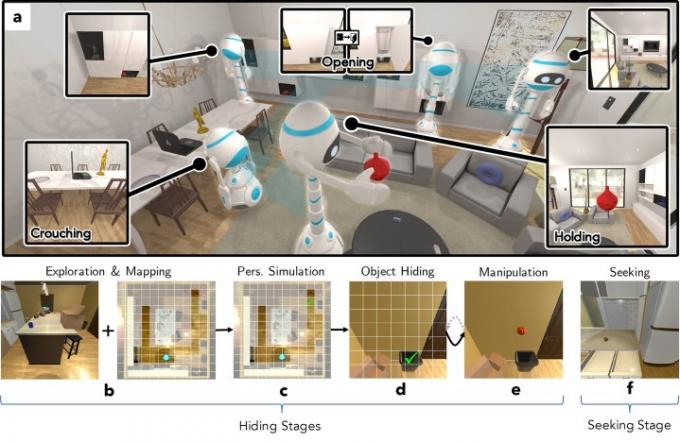
"I [vårt nya] arbete ville vi förstå hur A.I. agenter kan lära sig om en realistisk miljö genom att spela ett interaktivt spel inom den, säger Weihs. "För att svara på den här frågan utbildade vi två agenter att spela Cache, en variant av kurragömma, med hjälp av kontradiktorisk förstärkningsinlärning inom högtrohet AI2-THOR miljö. Genom det här spelet upptäckte vi att våra agenter lärde sig att representera individuella bilder och närma sig metodernas prestanda krävde miljontals handmärkta bilder - och började till och med utveckla några kognitiva primitiver som ofta studeras av [utvecklings] psykologer.”
Spelets regler
Till skillnad från vanliga kurragömma turas robotarna i Cache om att gömma föremål som toalettkolvar, bröd, tomater och mer, som var och en har sin egen individuella geometri. De två agenterna - den ena en gömman, den andra en sökare - tävlar sedan för att se om den ena framgångsrikt kan dölja föremålet för den andra. Detta innebär ett antal utmaningar, inklusive utforskning och kartläggning, förståelse av perspektiv, gömma sig, objektmanipulation och sökande. Allt är exakt simulerat, till och med kravet att gömman ska kunna manipulera föremålet i sin hand och inte tappa det.
Använda djup förstärkningsinlärning — ett maskininlärningsparadigm baserat på att lära sig att vidta åtgärder i en miljö för att maximera belöningen — robotarna blir bättre och bättre på att gömma föremålen, såväl som att söka dem ut.
"Vad som gör det här så svårt för A.I.s är att de inte ser världen som vi gör," sa Weihs. "Miljarder år av evolution har gjort det så att våra hjärnor, även som spädbarn, effektivt översätter fotoner till begrepp. Å andra sidan har en A.I. börjar från början och ser sin värld som ett enormt rutnät av siffror som den sedan måste lära sig att avkoda till mening. Dessutom, till skillnad från i schack, där världen är prydligt inrymd i 64 rutor, fångar varje bild som ses av agenten bara en liten del av miljön, och därför måste den integrera sina observationer genom tiden för att bilda en sammanhängande förståelse av värld."
För att vara tydlig handlar det här senaste arbetet inte om att bygga en superintelligent A.I. I filmer som Terminator 2: Judgment Day, uppnår Skynet-superdatorn självkännedom exakt klockan 02.14 Eastern Time den 29 augusti 1997. Trots datumet, nu nästan ett kvartssekel i vår kollektiva backspegel, verkar det osannolikt att det kommer att finnas en så exakt vändpunkt när vanliga A.I. blir AGI. Istället kommer fler och fler beräkningsbaserade frukter - lågt hängande och högt hängande - att plockas tills vi äntligen har något som närmar sig en generaliserad intelligens över flera domäner.
Hårda grejer är lätta, lätta grejer är svårt
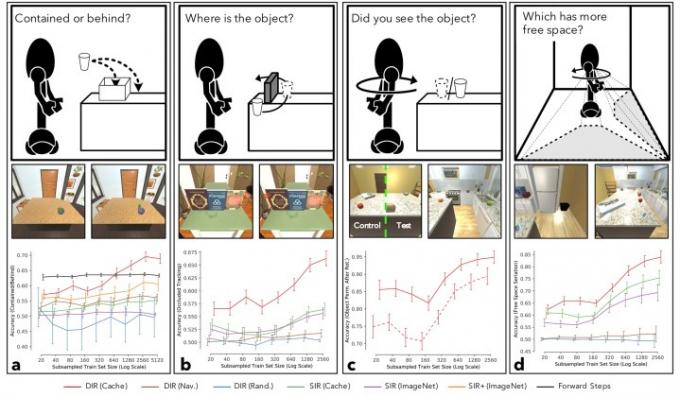
Forskare har traditionellt graviterat mot komplexa problem för A.I. att lösa utifrån idén att, om de svåra problemen kan lösas, bör de enkla problemen inte ligga för långt efter. Om du kan simulera en vuxens beslutsfattande, kan idéer som objektpermanens (tanken att objekt fortfarande existerar när vi inte kan se dem) som ett barn lär sig inom de första månaderna av sitt liv bevisar verkligen det svår? Svaret är ja - och denna paradox att, när det kommer till A.I., hårda saker är ofta lätta och lätta är svåra, är vad arbete som detta syftar till att ta itu med.
"Det vanligaste paradigmet för att träna A.I. agenter [involverar] enorma, manuellt märkta datamängder som är snävt fokuserade på en enda uppgift – till exempel att känna igen objekt”, sa Weihs. "Även om detta tillvägagångssätt har haft stor framgång, tror jag att det är optimistiskt att tro att vi manuellt kan skapa tillräckligt många datauppsättningar för att producera en A.I. agent som kan agera intelligent i den verkliga världen, kommunicera med människor och lösa alla möjliga problem som den inte har stött på tidigare. För att göra detta tror jag att vi kommer att behöva låta agenter lära sig de grundläggande kognitiva primitiv som vi tar för givna genom att låta dem interagera fritt med sin värld. Vårt arbete visar att genom att använda spel för att motivera A.I. agenter att interagera med och utforska sin värld resulterar i att de börjar lära sig dessa primitiver — och visar därigenom att spelet är en lovande riktning bort från manuellt märkta datamängder och mot upplevelsemässig inlärning."
A papper som beskriver detta arbete kommer att presenteras vid den kommande internationella konferensen om läranderepresentationer 2021.
Redaktörens rekommendationer
- Optiska illusioner kan hjälpa oss att bygga nästa generations AI
- Den roliga formeln: Varför maskingenererad humor är A.I.s heliga gral.
- Läs den kusligt vackra "syntetiska skriften" av en A.I. som tror att det är Gud
- Algoritmisk arkitektur: Ska vi låta A.I. designa byggnader åt oss?
- Känslokännande A.I. är här, och det kan vara i din nästa anställningsintervju



