Menu-opties om OCR-tekstherkenning te kiezen
Wanneer een papieren document wordt gescand en opgeslagen in PDF-indeling, weet een computer het verschil niet tussen uw gescande tekstpagina en een foto. U kunt dus geen tekst op de pagina zoeken of selecteren om te kopiëren en plakken. Als u tekst wilt zoeken of selecteren, moet u optische tekenherkenning (OCR) op het document uitvoeren. Adobe Acrobat Professional biedt deze functionaliteit, maar de gratis versie van Adobe Acrobat niet. Als u Acrobat Professional niet hebt, houd er dan rekening mee dat er andere software dan Acrobat Professional bestaat om OCR op een PDF-document uit te voeren, en dat u deze kunt vinden door op internet te zoeken.
Stap 1
Laad Adobe Acrobat Professional. De OCR-functie van Acrobat Professional is niet beschikbaar via de webbrowserplug-in, dus het daadwerkelijke programma moet worden geladen.
Video van de dag
Stap 2
Laad een PDF-document met tekst die u niet kunt selecteren om te kopiëren en plakken. Dergelijke documenten worden meestal geproduceerd door een document te scannen en het document op te slaan in Adobe Acrobat PDF-indeling. (Zie bronnen voor een voorbeelddocument, als u ermee wilt oefenen.)
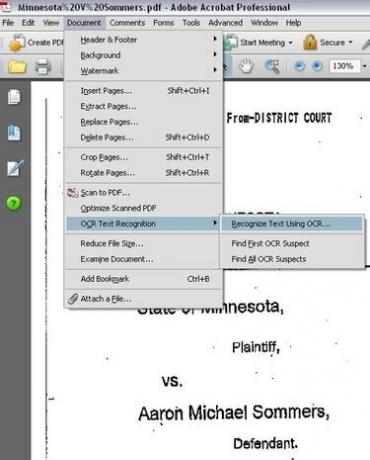
Stap 3
Menu-opties om OCR-tekstherkenning te kiezen
Voer OCR uit op het document. Klik in Adobe Acrobat Professional op het menu "Document", selecteer vervolgens "OCR-tekstherkenning" en klik vervolgens op "Tekst herkennen met OCR".
Stap 4
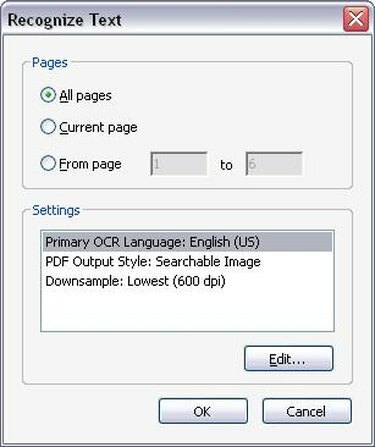
OCR-opties
Kies de toepasselijke OCR-opties. Zodra u op "Herken tekst met OCR" klikt, verschijnt er een nieuw venster waarin u wordt gevraagd het paginabereik te selecteren waarop u OCR wilt uitvoeren. U kunt OCR uitvoeren op het volledige PDF-bestand, of u kunt de OCR-herkenning beperken tot slechts enkele pagina's. Nadat u hebt gekozen op hoeveel pagina's u OCR wilt uitvoeren, klikt u op 'OK'. Acrobat Professional begint nu de tekst op de pagina's van uw document te herkennen.
Stap 5
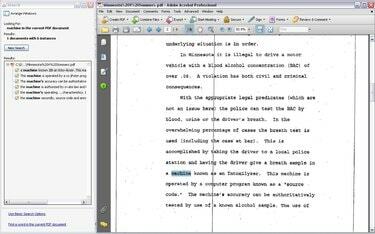
OCR: Creëert een doorzoekbaar en selecteerbaar PDF-bestand
Zoek naar tekst, zodra OCR is voltooid, en kopieer en plak tekst net zoals u zou kunnen met een PDF die is gedestilleerd uit Microsoft Word. Houd er echter rekening mee dat de OCR-technologie niet perfect is. OCR herkent bepaalde woorden mogelijk niet goed en kan tekst volledig missen. OCR werkt het beste met perfect heldere afbeeldingen van de tekst, iets wat niet altijd mogelijk is met gescande documenten.



