이미지 크레디트: 론 프라이스
NS 정상 확률 플롯, 켜짐 여부 확률 종이 값 집합이 정규 분포에서 유래했는지 여부를 결정하는 데 도움이 될 수 있습니다. 이 결정을 내리려면 다음 확률을 적용해야 합니다. 정규 분포, 손으로 했다면 확률 종이가 나오는 곳입니다. Microsoft Excel에는 확률 용지에 대한 실제 인쇄 레이아웃이 없지만 이 형식을 시뮬레이션하기 위해 차트를 조정할 수 있습니다.
1단계: 데이터 세트 입력
이미지 크레디트: 론 프라이스
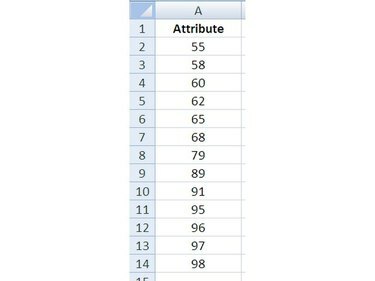
소규모 샘플링의 결과인 데이터가 있고 이러한 데이터가 정규 분포에서 나온 것인지 알고 싶습니다. 엑셀 열기 그리고 시작하다 워크시트의 데이터.
오늘의 비디오
팁
이 프로세스 또는 모든 프로세스의 각 단계를 완료한 후에는 항상 작업, 즉 Excel 통합 문서를 저장하는 것이 좋습니다.
2단계: 정렬할 데이터 선택
이미지 크레디트: 론 프라이스
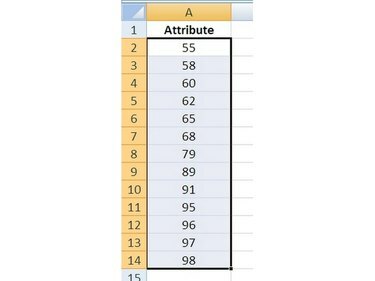
선택하다 첫 번째 값(제목 아님)이 있는 셀을 클릭하여 정렬할 데이터 보유 마우스 버튼을 아래로, 이동하다 마지막 값으로 마우스 포인터를 이동하고 풀어 주다 버튼. 데이터 셀은 이제 음영 처리되어야 하며 이는 "선택됨"을 의미합니다.
3단계: 데이터 정렬
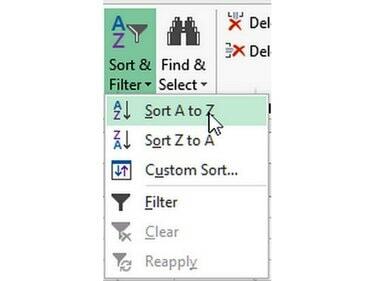
이미지 크레디트: 론 프라이스
딸깍 하는 소리 Excel 리본의 홈 탭에서 딸깍 하는 소리 정렬 및 필터 버튼을 눌러 메뉴를 표시합니다. 딸깍 하는 소리 이전 단계에서 선택한 데이터를 정렬하려면 A에서 Z로(또는 낮음에서 높음으로) 정렬합니다.
4단계: 값에 번호 매기기
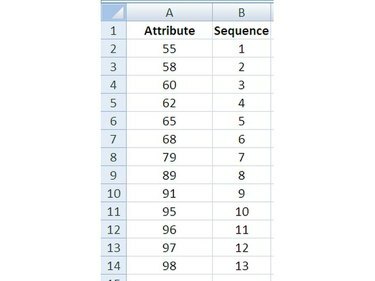
이미지 크레디트: 론 프라이스
데이터 값에 인접한 열에서 시작하다 각 값에 대해 위에서 아래로 1부터 1까지 번호를 매기는 일련 번호 N, 예에서 n = 13입니다.
5단계: 평균 계산
데이터와 동일한 워크시트의 빈 셀에서 시작하다 AVERAGE() 함수를 사용하여 계산 산술 평균 데이터 세트:
=AVERAGE(First_Cell: Last_Cell)
First_Cell 및 Last_Cell은 데이터 값 범위의 시작 및 끝 셀을 참조합니다. 예제에서 함수 문은 =AVERAGE(B2:B14)입니다..
팁
나중에 참조할 수 있도록 이 값과 다른 계산된 값에 헤더 또는 레이블을 할당할 수 있습니다.
6단계: 표준 편차 계산
평균을 계산한 셀에 인접하여 STDEV() 함수를 입력하여 평균을 계산합니다. 표준 편차 데이터 세트의 값:
=STDEV(First_Cell: Last_Cell)
First_Cell 및 Last_Cell은 데이터 값 범위의 시작 및 끝 셀을 참조합니다. 예제에서 함수 문은 =STDEV(B2:B14)입니다..
팁
STDEV 및 STDEVP는 데이터 샘플에 사용하기 위한 함수입니다. STDEV
7단계: 누적 확률 계산
NORMDIST() 함수를 입력하여 각 값의 누적 확률을 완성합니다.
플롯을 생성하는 데 필요한 데이터를 완성하려면 값에 순서대로 번호를 매겨야 하며 연결된 z-값이 결정되고 각 값의 확률과 함께 모든 누적 확률이 가치.