
पहली सर्वनाशकारी चेतावनी: हमारा डेटा भंडारण ख़त्म हो रहा है।
अंतर्वस्तु
- डेटा, डेटा, हर जगह
- क्या डीएनए इसका उत्तर है?
- यह सब भंडारण के बारे में है
- संभावनाओं की कल्पना करें
संभावना यह है कि यह कोई ऐसी चीज़ नहीं है जिसके बारे में आपको हाल के वर्षों में बहुत अधिक चिंता करनी पड़ी हो। एक समय था, बहुत पहले नहीं, जब आपके कंप्यूटर की सीमित हार्ड ड्राइव में आपके पास उपलब्ध सारा भंडारण होता था। उस सीमा तक पहुंचें (जो, मेरे अपने पहले कंप्यूटर के मामले में, 100एमबी से कम थी) और आपने फ्लॉपी डिस्क और अन्य स्थानीय बाह्य भंडारण का सहारा लिया। जब आपके पास वह भी ख़त्म हो गया, तो आपको हटा दिया गया।
प्रत्येक दिन, लगभग 2.5 क्विंटिलियन बाइट्स डेटा बनाया जाता है, जो 3.7 अरब मनुष्यों के सौजन्य से है जो अब इंटरनेट का उपयोग करते हैं।
हम और नहीं हटाते. न ही कंपनियाँ, विशेष रूप से उनका मूल्यांकन उनके पास मौजूद डेटा के आधार पर किया जाता है। इसके बजाय, हम बस अपनी फ़ाइलों को क्लाउड पर भेज देते हैं, जिसका नाम ही अल्पकालिक और ईथर है; किसी भी वास्तविक भौतिकता का अभाव। डेटा कहाँ संग्रहीत है? इससे कोई फर्क नहीं पड़ता जब तक हम इसे वापस पा सकते हैं। क्लाउड स्टोरेज ख़त्म होने के खतरे क्या हैं? अधिक शानदार खाली स्थान अनलॉक करने के लिए अपने मासिक सदस्यता भुगतान को बढ़ाने के अलावा, यह बहुत कम प्रतीत होता है।
संबंधित
- अमेरिकी सरकार और बड़ी तकनीकें कोरोनोवायरस से लड़ने के लिए स्थान डेटा का उपयोग करना चाहती हैं
- डीएनए, लेजर-नक़्क़ाशीदार ग्लास, और उससे आगे: डेटा भंडारण के भविष्य पर एक नज़र
- माइक्रोसॉफ्ट की नवीनतम सफलता डीएनए-आधारित डेटा केंद्रों को संभव बना सकती है
परिणामस्वरूप, यह विचार कि एक दिन हमारा डेटा संग्रहण समाप्त हो जाएगा, आपके दिमाग में आना उतना ही कठिन है चारों ओर इस सुझाव के रूप में कि हम पानी को खत्म कर सकते हैं: वह गौरवशाली मुक्त संसाधन जो गिरता है आकाश। लेकिन 2018 वो साल है जिसमें केप टाउन, साउथ अफ्रीका आया पानी ख़त्म होने के बिल्कुल करीब. और हमारा डेटा संग्रहण भी ख़त्म हो सकता है।
डेटा, डेटा, हर जगह
इसका कारण वह अकल्पनीय गति है जिस पर हम वर्तमान में डेटा का उत्पादन करते हैं। प्रत्येक दिन, लगभग 2.5 क्विंटिलियन बाइट्स डेटा बनाया जाता है, जो 3.7 अरब मनुष्यों के सौजन्य से है जो अब इंटरनेट का उपयोग करते हैं। अकेले पिछले दो वर्षों में, दुनिया का 90 प्रतिशत डेटा आश्चर्यजनक रूप से तैयार किया गया है। इंटरनेट ऑफ थिंग्स से जुड़े स्मार्ट उपकरणों की बढ़ती संख्या के साथ, यह आंकड़ा काफी बढ़ने वाला है।

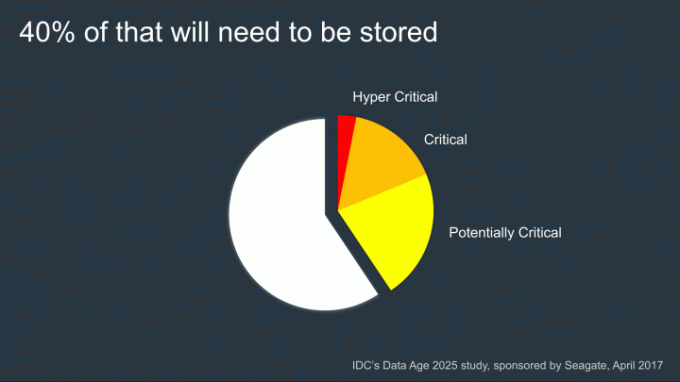
डेटा स्टोरेज कंपनी के सीईओ और सह-संस्थापक ह्यूनजुन पार्क ने कहा, "जब हम क्लाउड स्टोरेज के बारे में सोचते हैं, तो हम डेटा के इन अनंत भंडारों के बारे में सोचते हैं।" सूची, डिजिटल ट्रेंड्स को बताया। “लेकिन क्लाउड वास्तव में किसी और का कंप्यूटर है। अधिकांश लोगों को यह एहसास नहीं है कि हम इतना अधिक डेटा उत्पन्न कर रहे हैं कि जिस गति से हम इसे उत्पन्न कर रहे हैं वह इसे संग्रहीत करने की हमारी क्षमता से कहीं अधिक है। निकट भविष्य में, हम जो उपयोगी डेटा पैदा कर रहे हैं और हम पारंपरिक माध्यमों का उपयोग करके इसे कैसे संग्रहीत करने में सक्षम हैं, उसके बीच एक बड़ा अंतर होने वाला है।
कैटलॉग ने ऐसी तकनीक विकसित की है जिसके बारे में उनका मानना है कि यह हमारे डेटा संग्रहीत करने के तरीके को बदल सकती है।
चूंकि क्लाउड स्टोरेज कंपनियां नए डेटा सेंटर बनाने और अपने मौजूदा केंद्रों का तेजी से विस्तार करने में व्यस्त हैं, इसलिए यह पता लगाना मुश्किल है कि कब हमारी डेटा स्टोरेज क्षमता खत्म हो जाएगी। कोई फिल्म-शैली की उलटी गिनती घड़ी नहीं है। पार्क के अनुसार, हालाँकि, 2025 की शुरुआत में मानव जाति ने संचयी रूप से 160 ज़ेटाबाइट से अधिक डेटा का उत्पादन किया होगा। (यदि आप सोच रहे हैं कि एक ज़ेटाबाइट एक ट्रिलियन गीगाबाइट है।) हम इसमें से कितना संग्रहित कर पाएंगे? पार्क का सुझाव है कि इसका लगभग 12.5 प्रतिशत।
जाहिर है, कुछ करने की जरूरत है.
क्या डीएनए इसका उत्तर है?
यहीं पर पार्क और साथी एमआईटी वैज्ञानिक और सह-संस्थापक नथानिएल रोक्वेट तस्वीर में प्रवेश करते हैं। उनके स्टार्टअप कैटलॉग ने ऐसी तकनीक विकसित की है, जिसके बारे में उनका मानना है कि यह डेटा स्टोरेज को बदल सकती है, जैसा कि हम जानते हैं; अनुमति देना, या ऐसा वे दावा करते हैं, दुनिया के संपूर्ण डेटा को एक कोट कोठरी के आकार की जगह में आराम से फिट करने की अनुमति देता है।

कैटलॉग का समाधान? डेटा को DNA में एनकोड करके। यह माइकल क्रिक्टन के उपन्यास के कथानक जैसा लग सकता है, लेकिन उनका स्केलेबल और किफायती समाधान गंभीर है, और ऐसा है स्टैनफोर्ड और हार्वर्ड के प्रमुख प्रोफेसरों के समर्थन के साथ-साथ अब तक उद्यम निधि में $9 मिलियन प्राप्त हुए विश्वविद्यालय.
"मुझसे अक्सर एक सवाल पूछा जाता है, 'हम किसका डीएनए उपयोग कर रहे हैं?'" पार्क हँसे। "लोग डरते हैं कि हम लोगों से डीएनए ले लेंगे और उन्हें म्यूटेंट या इस तरह की चीज़ों में बदल देंगे।"
वर्षों से बाधाओं ने डीएनए को अपनी विशाल डेटा भंडारण क्षमता तक पहुंचने से रोक दिया है।
ऐसा नहीं है, हमें यह स्पष्ट करना चाहिए कि कैटलॉग क्या कर रहा है। कंपनी जिस डीएनए में डेटा को कोड कर रही है वह एक सिंथेटिक पॉलिमर है। यह ऐसा कुछ नहीं है जो जैविक उत्पत्ति से आता है, और आधार जोड़े की श्रृंखला जिसमें डेटा को कोडित किया जाता है, एक और शून्य की श्रृंखला के रूप में, किसी भी जीवित चीज़ के लिए कोड नहीं है। लेकिन फिर भी अंतिम उत्पाद जीवित कोशिका में पाई जाने वाली किसी चीज़ से जैविक रूप से अप्रभेद्य है।
डीएनए के एक संभावित भंडारण विधि होने के विचार पर अब दशकों से अनुमान लगाया जा रहा है, वस्तुतः तब से जब जेम्स वॉटसन और फ्रांसिस क्रिक ने 1953 में डबल हेलिक्स की खोज की थी। हालाँकि, अब तक ऐसी कई बाधाएँ आई हैं, जिन्होंने इसे इसके अनुरूप चलने से रोक दिया है कम्प्यूटेशनल डेटा भंडारण समाधान के रूप में व्यापक संभावनाएं.
डीएनए-आधारित डेटा भंडारण पर पारंपरिक सोच नए डीएनए अणुओं के संश्लेषण पर केंद्रित है; डीएनए के चार बेस जोड़े के अनुक्रम में बिट्स के अनुक्रम को मैप करना और उन सभी संख्याओं का प्रतिनिधित्व करने के लिए पर्याप्त अणु बनाना जिन्हें आप संग्रहीत करना चाहते हैं। समस्या यह है कि यह प्रक्रिया धीमी और महंगी है, जब डेटा संग्रहीत करने की बात आती है तो दोनों में काफी बाधाएं होती हैं।


कैटलॉग का दृष्टिकोण संश्लेषण प्रक्रिया को एन्कोडिंग प्रक्रिया से अलग करने पर आधारित है। अनिवार्य रूप से, कंपनी कुछ अलग-अलग अणुओं की भारी संख्या में उत्पादन करती है (इसे बहुत सस्ता बनाती है) और फिर पूर्वनिर्मित अणुओं से भारी विविधता उत्पन्न करके जानकारी को एन्कोड करती है।
सादृश्य के रूप में, कैटलॉग ने आपके सभी डेटा को हार्ड-वायर्ड के साथ कस्टम हार्ड ड्राइव के निर्माण के पिछले दृष्टिकोण की तुलना की। अलग-अलग डेटा संग्रहीत करने का मतलब है शुरू से ही एक पूरी नई हार्ड ड्राइव बनाना। उनका सुझाव है कि उनका दृष्टिकोण खाली हार्ड ड्राइव का बड़े पैमाने पर उत्पादन करने और फिर आवश्यकता पड़ने पर उसे एन्कोडेड जानकारी से भरने जैसा है।
यह सब भंडारण के बारे में है
इस सब का रोमांचक हिस्सा डेटा की आश्चर्यजनक मात्रा है जिसे यह संग्रहीत कर सकता है। अवधारणा के प्रमाण के रूप में, कैटलॉग ने पुस्तकों को एन्कोड करने के लिए अपनी तकनीक का उपयोग किया है गैलक्सी के लिए सहयात्री मार्गदर्शिका डीएनए में. लेकिन संभावनाओं की तुलना में यह कुछ भी नहीं है।
शुरू से अंत तक, डीएनए से डेटा पढ़ने में कम से कम कई घंटे लगेंगे।
पार्क ने कहा, "यदि आप सेब की तुलना सेब से कर रहे हैं, तो आप जो बिट्स समान मात्रा में स्टोर कर सकते हैं, वह सॉलिड-स्टेट ड्राइव के सूचनात्मक घनत्व से लगभग 1 मिलियन गुना अधिक निकलता है।" "जो कुछ भी आप फ्लैश ड्राइव में स्टोर कर सकते हैं, यदि आप इसे डीएनए में कर रहे हैं तो आप उसी वॉल्यूम में उसका 1 मिलियन गुना स्टोर कर सकते हैं।"
हालाँकि, सॉलिड-स्टेट ड्राइव के साथ तुलना सटीक नहीं है। डीएनए एक ही वॉल्यूम में कहीं अधिक जानकारी संग्रहीत करने में सक्षम हो सकता है, लेकिन इसमें यूएसबी-कनेक्टेड फ्लैश ड्राइव की तत्काल पहुंच नहीं है। कैटलॉग का दृष्टिकोण डेटा को सिंथेटिक पॉलिमर की एक ठोस गोली में बदल देता है।
आपके डेटा तक पहुंचने के लिए, वैज्ञानिकों को उक्त गोली लेनी होगी, पानी डालकर इसे पुनः हाइड्रेट करना होगा और फिर डीएनए सीक्वेंसर का उपयोग करके इसे पढ़ना होगा। यह डीएनए के आधार जोड़े प्रदान करता है, जो बदले में, आपके डेटा को फिर से इकट्ठा करने वाले एक और शून्य की गणना करने के लिए उपयोग किया जा सकता है। प्रारंभ से अंत तक, प्रक्रिया में कम से कम कई घंटे लगेंगे।

इस कारण से, कैटलॉग प्रारंभ में ऐसे बाज़ार को लक्षित कर रहा है जो इस प्रकार की देरी का आदी है: संग्रह बाज़ार। यह उस प्रकार का डेटा है जो वर्तमान में ट्रैक रखने के लिए उपयोग किए जाने वाले चुंबकीय टेप जैसे प्रारूपों पर संग्रहीत किया जाता है ऐसी जानकारी जिसके बारे में आप उम्मीद कर सकते हैं कि उसे दोबारा देखने की ज़रूरत नहीं होगी, लेकिन फिर भी उसे लटकाए रखना महत्वपूर्ण है पर. (अपने फ्रिज की वारंटी के कॉर्पोरेट समकक्ष की कल्पना करें।)
लेकिन क्या कभी ऐसा कोई बिंदु है जब यह औसत उपयोगकर्ता के लिए मायने रखेगा? आख़िरकार, जैसा कि हमने इस लेख के शीर्ष पर बताया है, हममें से अधिकांश लोग वास्तव में अपने डेटा और इसे कहाँ रखा जाता है, इसके बारे में इतना नहीं सोचते हैं। क्या यह चुंबकीय टेप पर है? क्या यह सॉलिड-स्टेट स्टोरेज पर है? जब तक हमें इसकी आवश्यकता होती है, तब तक हमें कोई आपत्ति नहीं होती।
डीएनए-आधारित डेटा एन्कोडिंग एक दीर्घकालिक भंडारण विकल्प होने की संभावना है, जबकि अल्पकालिक डेटा अन्य रूप लेता है।
जानकारी प्राप्त करने में जितना समय लगता है, उसके कारण कभी भी ऐसा कोई बिंदु आने की संभावना नहीं है उदाहरण के लिए, आपकी Google क्लाउड जानकारी डीएनए के विशाल भंडार में या माउंटेन में संगमरमर जैसी छर्रों की एक श्रृंखला के रूप में संग्रहीत है देखें, सीए. क्या कैटलॉग व्यवसायों के लिए अपनी अवधारणा को साबित करने में सक्षम होना चाहिए, यह एक दीर्घकालिक भंडारण विकल्प होने की संभावना है, जबकि अल्पकालिक डेटा अन्य रूप लेता है।
संभावनाओं की कल्पना करें

हालाँकि, वहाँ रोमांचक विज्ञान-कल्पना की संभावनाएँ हैं। पार्क ने कहा, "एक चमड़े के नीचे की गोली की कल्पना करें जिसमें आपके सभी स्वास्थ्य डेटा, आपके सभी एमआरए स्कैन, आपके रक्त परीक्षण, आपके दंत चिकित्सक से एक्स-रे शामिल हों।" “आप हमेशा चाहेंगे कि वह डेटा आपके लिए बहुत सुलभ हो, लेकिन आप जरूरी नहीं कि इसे कहीं क्लाउड पर, या किसी अस्पताल में असुरक्षित सर्वर पर रखें। यदि वह डीएनए के रूप में आपके पास है, तो आप उस डेटा को भौतिक रूप से नियंत्रित कर सकते हैं और उस तक पहुंच सकते हैं, साथ ही यह सुनिश्चित कर सकते हैं कि केवल अधिकृत डॉक्टरों की ही उस तक पहुंच हो सकती है।
आख़िरकार, जैसा कि वह बताते हैं, आज सभी अस्पतालों में डीएनए सीक्वेंसर हैं। उन्होंने कहा, "मैं यह नहीं कह रहा हूं कि हम अभी इस पर काम कर रहे हैं, लेकिन यह एक संभावित भविष्य है।"
दुनिया के सामने अपनी नई कंपनी की घोषणा करने के बाद, कैटलॉग अब कुछ पायलट परियोजनाओं को पूरा करने पर ध्यान केंद्रित कर रहा है ताकि यह प्रदर्शित किया जा सके कि इस तकनीक का प्रभावी ढंग से उपयोग कैसे किया जा सकता है। उन्होंने कहा, "ये वैज्ञानिक चुनौतियां नहीं हैं जिन्हें हमने हल करने के लिए छोड़ा है, बल्कि यांत्रिक अनुकूलन समस्याएं हैं।"
अपने स्वयं के स्वीकारोक्ति के अनुसार, इस क्षेत्र में प्रवेश करना क्योंकि यह एक बड़े तकनीकी दृष्टिकोण की तरह लग रहा था समस्या, पार्क अब आश्वस्त है कि डीएनए डेटा भंडारण हमारी सबसे महत्वपूर्ण प्रौद्योगिकियों में से एक बन सकता है समय।
हेक, जब मानव इतिहास को संग्रहीत करने में सक्षम होने की बात आती है जैसा कि हम जानते हैं, तो असहमत होना मुश्किल है। "यह हमारे जीवन जीने के तरीके को संरक्षित करने के बारे में है जैसा कि हम जानते हैं," उन्होंने समझाया।
संपादकों की सिफ़ारिशें
- क्या पुराने जमाने के चुंबकीय टेप भविष्य का डेटा भंडारण माध्यम हैं?
- चीन अपराधियों के चेहरों का अनुमान लगाने के लिए विवादास्पद डीएनए विश्लेषण का उपयोग करना चाहता है
- यह बायोटेक स्टार्टअप आपके डीएनए को चांद पर एक तिजोरी में रखना चाहता है
- कैल्टेक वैज्ञानिकों ने दुनिया के सबसे छोटे गेम टिक-टैक-टो को खेलने के लिए डीएनए का उपयोग किया
- सटीक दवा डीएनए पर निर्भर करती है, लेकिन अपना थूक बाहर भेजने में अभी भी जोखिम है


