Menüüvalikud OCR-i tekstituvastuse valimiseks
Kui paberkoopia dokument skannitakse ja PDF-vormingus salvestatakse, ei tea arvuti teie skannitud tekstilehe ja foto erinevust. Seega ei saa te lehelt kopeerimiseks ja kleepimiseks teksti otsida ega valida. Kui soovite teksti otsida või valida, peate dokumendil käivitama optilise märgituvastuse (OCR). Adobe Acrobat Professional pakub seda funktsiooni, kuid Adobe Acrobati tasuta versioon mitte. Kui teil pole Acrobat Professionali, võtke arvesse, et PDF-dokumendis OCR-i käitamiseks on olemas ka muu tarkvara peale Acrobat Professionali ja selle leiate veebist otsides.
Samm 1
Laadige Adobe Acrobat Professional. Acrobat Professionali OCR-funktsioon pole veebibrauseri pistikprogrammi kaudu saadaval, seega on vaja tegelik programm laadida.
Päeva video
2. samm
Laadige PDF-dokument tekstiga, mida te ei saa kopeerimiseks ja kleepimiseks valida. Sellised dokumendid koostatakse tavaliselt dokumendi skaneerimisel ja dokumendi salvestamisel Adobe Acrobat PDF-vormingus. (Kui soovite sellega harjutada, vaadake näidisdokumendi allikaid.)
3. samm
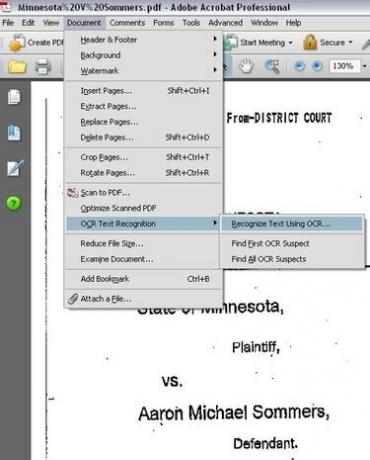
Menüüvalikud OCR-i tekstituvastuse valimiseks
Käivitage dokumendis OCR. Adobe Acrobat Professionalis klõpsake menüül "Dokument", seejärel valige "OCR-i tekstituvastus" ja seejärel klõpsake "Tuvasta tekst OCR-i abil".
4. samm
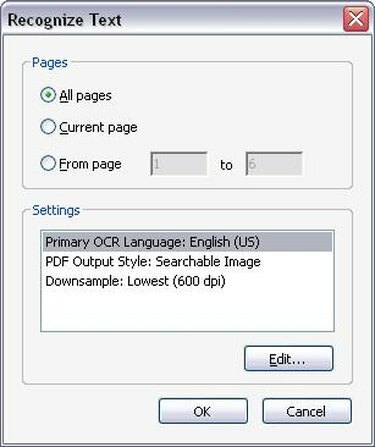
OCR-i valikud
Valige sobivad OCR-i valikud. Kui klõpsate "Tuvasta teksti OCR-i abil", ilmub uus aken, milles palutakse teil valida lehevahemik, millel soovite OCR-i käitada. Saate käivitada OCR-i kogu PDF-failis või piirata OCR-i tuvastamist vaid mõne leheküljega. Kui olete valinud, mitu lehekülge soovite OCR-i käivitada, klõpsake "OK". Acrobat Professional hakkab nüüd teie dokumendi lehtedel olevat teksti ära tundma.
5. samm
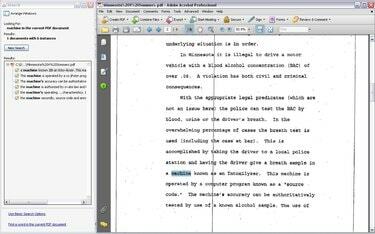
OCR: loob otsitava ja valitava PDF-faili
Otsige teksti, kui OCR on lõpetatud, ning kopeerige ja kleepige tekst täpselt nii, nagu võiksite seda teha Microsoft Wordist destilleeritud PDF-failiga. Pange tähele, et OCR-tehnoloogia pole täiuslik. OCR ei pruugi teatud sõnu õigesti ära tunda ja osa tekstist võib täielikult puududa. OCR töötab kõige paremini täiesti selgete tekstipiltidega, mis pole alati skannitud dokumentide puhul võimalik.



