Deep learning er en særlig undergruppe af maskinelæring (mekanikken i kunstig intelligens). Selvom denne gren af programmering kan blive meget kompleks, startede den med et meget simpelt spørgsmål: "Hvis vi vil have et computersystem til at handle intelligent, hvorfor modellerer vi det så ikke efter den menneskelige hjerne?"
Den tanke affødte mange bestræbelser i de seneste årtier for at skabe algoritmer, der efterlignede den måde, den menneskelige hjerne fungerede på - og som kunne løse problemer, som mennesker gjorde. Disse bestræbelser har givet værdifulde, stadig mere kompetente analyseværktøjer, der bruges på mange forskellige områder.
Anbefalede videoer
Det neurale netværk og hvordan det bruges
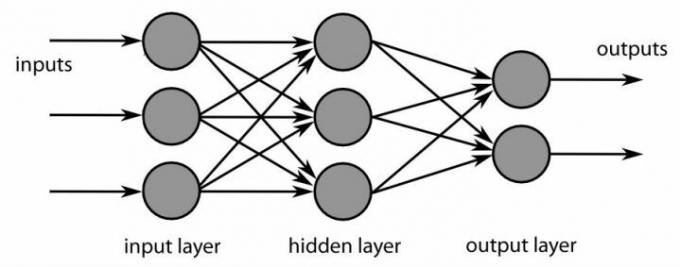
Dyb læring får sit navn fra, hvordan det bruges til at analysere "ustrukturerede" data, eller data, der ikke tidligere er blevet mærket af en anden kilde og muligvis skal defineres. Det kræver omhyggelig analyse af, hvad dataene er, og gentagne test af disse data for at ende med en endelig, brugbar konklusion. Computere er ikke traditionelt gode til at analysere ustrukturerede data som denne.
Relaterede
- A.I. oversættelsesværktøj kaster lys over musenes hemmelige sprog
- Ny 'skyggefuld' forskning fra MIT bruger skygger til at se, hvad kameraer ikke kan
- Kunstig intelligens kan nu identificere en fugl blot ved at se på et foto
Tænk over det med hensyn til at skrive: Hvis du havde ti personer til at skrive det samme ord, ville det ord se meget forskelligt ud fra hver person, fra sjusket til pænt og fra kursiv til tryk. Den menneskelige hjerne har ingen problemer med at forstå, at det hele er det samme ord, fordi den ved, hvordan ord, skrift, papir, blæk og personlige særheder fungerer. Et normalt computersystem ville dog ikke have nogen mulighed for at vide, at disse ord er ens, fordi de alle ser så forskellige ud.
Det bringer os til via neurale netværk, de algoritmer, der er specielt skabt til at efterligne den måde, neuronerne i hjernen interagerer på. Neurale netværk forsøger at analysere data på den måde, som et sind kan: Deres mål er at håndtere rodede data – som at skrive – og drage nyttige konklusioner, som de ord som skrivning forsøger at vise. Det er nemmest at forstå neurale netværk hvis vi deler dem op i tre vigtige dele:
Inputlaget: Ved inputlaget absorberer det neurale netværk alle de uklassificerede data, som det er givet. Dette betyder at opdele informationen i tal og omdanne dem til bits af ja-eller-nej-data eller "neuroner". Hvis du ville lære et neuralt netværk at genkende ord, så ville inputlaget være matematisk definere formen på hvert bogstav, opdele det i digitalt sprog, så netværket kan starte arbejder. Inputlaget kan være ret simpelt eller utrolig komplekst, afhængigt af hvor nemt det er at repræsentere noget matematisk.
De skjulte lag: I centrum af det neurale netværk er skjulte lag - alt fra ét til mange. Disse lag er lavet af deres egne digitale neuroner, som er designet til at aktivere eller ikke aktiveres baseret på det lag af neuroner, der går forud for dem. En enkelt neuron er en grundlæggende "hvis dette, så det“ model, men lag er lavet af lange kæder af neuroner, og mange forskellige lag kan påvirke hinanden og skabe meget komplekse resultater. Målet er at give det neurale netværk mulighed for at genkende mange forskellige funktioner og kombinere dem til en enkelt erkendelse, som et barn lære at genkende hvert bogstav og derefter danne dem sammen for at genkende et helt ord, selvom det ord er skrevet lidt sløset.
De skjulte lag er også der, hvor en masse dyb læringstræning foregår. For eksempel, hvis algoritmen ikke kunne genkende et ord nøjagtigt, sender programmører tilbage, "Beklager, det er ikke korrekt," og algoritmen ville justere, hvordan den vejede data, indtil den fandt det rigtige svar. Gentagelse af denne proces (programmører kan også justere vægte manuelt) giver det neurale netværk mulighed for at opbygge robuste skjulte lag, der er dygtig til at finde de rigtige svar gennem en masse forsøg og fejl plus noget udefrakommende instruktion - igen, meget ligesom den menneskelige hjerne arbejder. Som ovenstående billede viser, kan skjulte lag blive meget komplekse!
Outputlaget: Outputlaget har relativt få "neuroner", fordi det er her, de endelige beslutninger træffes. Her anvender det neurale netværk den endelige analyse, tager stilling til definitioner for dataene og drager de programmerede konklusioner baseret på disse definitioner. For eksempel: "Nok af dataene står i kø til at sige, at dette ord er sø, ikke bane." I sidste ende er alle data, der passerer gennem netværket, indsnævret til specifikke neuroner i outputlaget. Da det er her, målene realiseres, er det ofte en af de første dele af netværket, der skabes.
Ansøgninger

Hvis du bruger moderne teknologi, er chancerne gode for, at deep learning-algoritmer er på arbejde overalt omkring dig, hver dag. Hvad tænker du Alexa eller Google Assistant forstår dine stemmekommandoer? De bruger neurale netværk, der er blevet bygget til at forstå tale. Hvordan ved Google, hvad du søger efter, før du er færdig med at skrive? Mere dyb læring på arbejdet. Hvordan ignorerer dit sikkerhedskamera kæledyr, men genkender menneskelig bevægelse? Endnu en gang dyb læring.
Når som helst den software genkender menneskelige input, fra ansigtsgenkendelse for stemmeassistenter er deep learning sandsynligvis på arbejde et sted nedenunder. Men feltet har også mange andre nyttige anvendelser. Medicin er et særligt lovende felt, hvor avanceret deep learning bruges til at analysere DNA for fejl eller molekylære forbindelser for potentielle sundhedsmæssige fordele. På en mere fysisk front bruges deep learning i et voksende antal maskiner og køretøjer til at forudsige, hvornår udstyr skal vedligeholdes, før noget går alvorligt galt.
Fremtiden for dyb læring

Fremtiden for deep learning er særlig lys! Det fantastiske ved et neuralt netværk er, at det udmærker sig ved at håndtere en enorm mængde forskellige data (tænk på alt, hvad vores hjerner skal håndtere, hele tiden). Det er især relevant i vores æra med avancerede smarte sensorer, som kan samle utrolig meget information. Traditionelle computerløsninger begynder at kæmpe med at sortere, mærke og drage konklusioner ud fra så mange data.
Deep learning kan på den anden side håndtere de digitale bjerge af data, vi indsamler. Faktisk, jo større mængden af data er, jo mere effektiv bliver deep learning sammenlignet med andre analysemetoder. Det er derfor, organisationer som Google investere så meget i deep learning algoritmer, og hvorfor de sandsynligvis vil blive mere almindelige i fremtiden.
Og selvfølgelig robotterne. Lad os aldrig glemme robotterne.
Redaktørernes anbefalinger
- Deep-learning A.I. hjælper arkæologer med at oversætte gamle tavler
- Dyb læring A.I. kan efterligne forvrængningseffekterne af ikoniske guitarguder
- Tankelæsende A.I. analyserer dine hjernebølger for at gætte, hvilken video du ser
- Denne A.I.-drevne app kan spotte hudkræft med 95 procent nøjagtighed
- A.I. forskere skaber et ansigtsgenkendelsessystem til chimpanser



