Možnosti nabídky pro výběr OCR rozpoznávání textu
Když je tištěný dokument naskenován a uložen do formátu PDF, počítač nepozná rozdíl mezi naskenovanou stránkou textu a fotografií. Nemůžete tedy na stránce vyhledávat ani vybírat žádný text ke kopírování a vkládání. Pokud chcete vyhledávat nebo vybírat text, musíte v dokumentu spustit optické rozpoznávání znaků (OCR). Adobe Acrobat Professional tuto funkci poskytuje, ale bezplatná verze Adobe Acrobat ne. Pokud nemáte Acrobat Professional, vezměte prosím na vědomí, že pro spouštění OCR na dokumentu PDF existuje jiný software než Acrobat Professional, který lze najít prohledáním webu.
Krok 1
Načtěte Adobe Acrobat Professional. Funkce OCR aplikace Acrobat Professional není dostupná prostřednictvím zásuvného modulu webového prohlížeče, takže je nutné načíst skutečný program.
Video dne
Krok 2
Načtěte dokument PDF s textem, který nemůžete vybrat ke kopírování a vkládání. Takové dokumenty se obvykle vytvářejí naskenováním dokumentu a uložením dokumentu ve formátu Adobe Acrobat PDF. (Viz Zdroje pro ukázkový dokument, pokud si s ním chcete procvičit.)
Krok 3
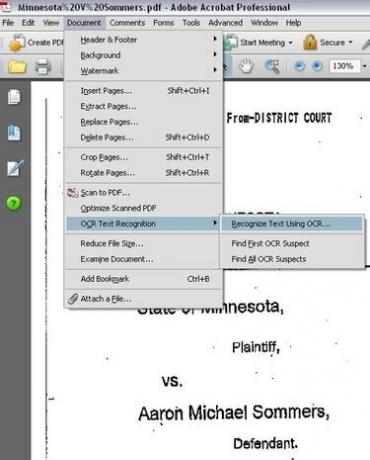
Možnosti nabídky pro výběr OCR rozpoznávání textu
Spusťte na dokumentu OCR. V Adobe Acrobat Professional klikněte na nabídku „Dokument“, vyberte „Rozpoznávání textu OCR“ a poté klikněte na „Rozpoznat text pomocí OCR“.
Krok 4
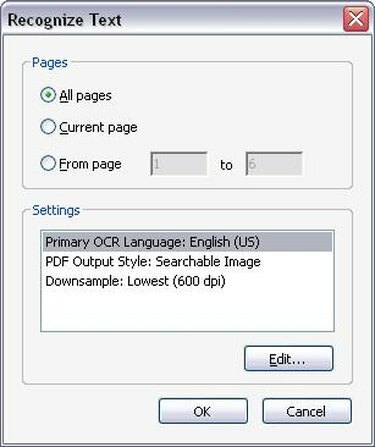
Možnosti OCR
Vyberte příslušné možnosti OCR. Po kliknutí na „Rozpoznat text pomocí OCR“ se objeví nové okno s výzvou k výběru rozsahu stránek, na kterém chcete spustit OCR. OCR můžete spustit na celý soubor PDF, nebo můžete rozpoznání OCR omezit pouze na několik stránek. Jakmile zvolíte, na kolika stránkách chcete spustit OCR, klikněte na „OK“. Acrobat Professional nyní začne rozpoznávat text na stránkách vašeho dokumentu.
Krok 5
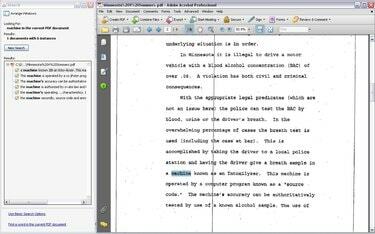
OCR: Vytvoří prohledávatelný a volitelný soubor PDF
Jakmile je OCR dokončeno, vyhledejte text a zkopírujte a vložte text stejně, jako byste mohli s PDF získaným z aplikace Microsoft Word. Pamatujte však, že technologie OCR není dokonalá. OCR nemusí správně rozpoznat některá slova a může zcela vynechat nějaký text. OCR funguje nejlépe s dokonale čistými obrázky textu, což u naskenovaných dokumentů není vždy možné.


